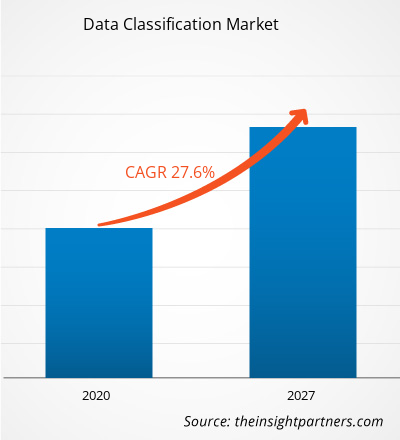
Der Markt für Datenklassifizierung wurde im Jahr 2019 auf 568,80 Millionen US-Dollar geschätzt und soll bis 2027 3.577,49 Millionen US-Dollar erreichen. Der Markt für Datenklassifizierung soll von 2020 bis 2027 mit einer durchschnittlichen jährlichen Wachstumsrate von 27,6 % wachsen.
Die Datenklassifizierung ist ein Tool, das enorme Datenmengen in verschiedene Registerkarten unterteilt, um das Beste daraus zu machen und gleichzeitig die Vertraulichkeit vertraulicher Daten zu wahren. Die Kommerzialisierung von Datenschutzgesetzen wie der DSGVO und dem Health Insurance Portability and Accountability Act ( HIPAA ) hat direkte Auswirkungen auf den weltweiten Umfang der Datenklassifizierung. Zunehmende Geschäftsdaten- und Cloud-Migrationen, zunehmende Identifizierung personenbezogener Daten, Bedrohung der Privatsphäre bei E-Mails, Nutzung von maschinellem Lernen und die Konvergenz von Datenverwaltung und Datenschutz sind einige der Faktoren, die eine bedeutende Rolle bei der Beschleunigung des Umfangs der Datenklassifizierung spielen. Die Datenklassifizierung erfährt weltweit eine starke Dynamik. Die Einführung von Datenklassifizierungstools zur Bekämpfung von Cyberbedrohungen ebnet den Weg für das Marktwachstum. Auch die zunehmende Betonung von Datenschutzgesetzen durch Regierungsbehörden in Ländern wie Großbritannien, den USA, Deutschland und Singapur treibt die Einführungsrate der Datenklassifizierung voran. Darüber hinaus beschleunigt die Integration hochentwickelter Technologien wie maschinelles Lernen und künstliche Intelligenz in Datenklassifizierungstools die Leistung und Produktivität des gesamten Unternehmens. Beispielsweise nutzen 40 % der US-Unternehmen ML, um ihre Verkaufs- und Marketingstrategien zu verbessern, und die europäischen Banken konnten mithilfe von ML ihre Produktverkäufe um 10 % steigern und ihre Abwanderungsraten um 20 % senken.
Der Markt für Datenklassifizierung ist segmentiert in Komponente, Anwendung, Vertikale und Geografie. Basierend auf der Komponente hielt das Lösungssegment den größten Anteil am globalen Markt für Datenklassifizierung. Die Datenklassifizierungslösung leitet Sicherheitskontrollen ab, die auf den jeweiligen Datensatz angewendet werden. Basierend auf der Anwendung dominierte das Segment Web-, Mobil- und E-Mail-Schutz den globalen Markt für Datenklassifizierung im Jahr 2019. Mit der zunehmenden Verwendung von E-Mail-, Mobil- und Webanwendungen zur Datenübertragung zwischen Unternehmen und Branchen sind die Tools für Datenschutz und Datenklassifizierung zu einer Notwendigkeit geworden. Basierend auf der Vertikalen trug das BFSI- Segment im Jahr 2019 einen erheblichen Anteil bei und wird voraussichtlich seine Dominanz während des Prognosezeitraums fortsetzen. Geografisch ist der Markt in fünf große Regionen segmentiert – Nordamerika, Europa, Asien-Pazifik ( APAC ), Naher Osten und Afrika ( MEA ) und Südamerika (SAM).
Passen Sie diesen Bericht Ihren Anforderungen an
Sie erhalten kostenlos individuelle Anpassungen an jedem Bericht, einschließlich Teilen dieses Berichts oder einer Analyse auf Länderebene, eines Excel-Datenpakets sowie tolle Angebote und Rabatte für Start-ups und Universitäten.
Markt für Datenklassifizierung:

- Holen Sie sich die wichtigsten Markttrends aus diesem Bericht.Dieses KOSTENLOSE Beispiel umfasst eine Datenanalyse von Markttrends bis hin zu Schätzungen und Prognosen.
Datenklassifizierung Markteinblicke
Regierungsmandate in Industrieländern
Die USA, Deutschland, Großbritannien und Singapur gehören zu den Ländern, in denen die Regierung IT-Unternehmen mit Gesetzen zur Datenverschlüsselung und zum Datenschutz reguliert hat, wodurch Technologieunternehmen in diesen Märkten Möglichkeiten finden, ihre Datenklassifizierungsdienste zu bewerben. Die Regierungen der USA und Großbritanniens haben dreistufige Datenklassifizierungssysteme für den öffentlichen Sektor eingerichtet. Sogar die Regierung in Washington ist über diesen Rahmen hinausgegangen und hat ein fünfstufiges Klassifizierungssystem eingeführt und wurde von den Open-Data-Befürwortern der Region sehr begrüßt, da es potenziellen Raum für die Branchenanbieter der Domäne geschaffen hat. Verschiedene Finanzdienstleistungsunternehmen wie Versicherungsunternehmen und Banken sind die Hauptnutzer von Datenklassifizierungslösungen, da sie mit großen Mengen personenbezogener Daten (PII) und staatlichen Datenschutzbestimmungen umgehen müssen.PII) and government data protection regulations.
Komponentenbasierte Markteinblicke
Auf der Grundlage der Komponenten ist der Markt für Datenklassifizierung in Lösungen und Dienste unterteilt. Titus, Boldon James, Digital Guardian, Spirion und Netwrix sind einige der führenden Akteure auf dem Markt, die die Anforderungen an Datenschutz und Datenklassifizierung erfüllen. Die Unternehmen bieten ein komplettes Datenklassifizierungstool zusammen mit einer Reihe von Diensten an, um die ordnungsgemäße Leistung der Lösung sicherzustellen.
Anwendungsbasierte Markteinblicke
Basierend auf der Anwendung ist der Markt für Datenklassifizierung in Governance, Risiko und Compliance, Web-, Mobil- und E-Mail-Schutz und Sonstiges segmentiert.
Vertikale Markteinblicke
Basierend auf der vertikalen Ebene ist der Markt für Datenklassifizierung in folgende Segmente unterteilt: BFSI, IT und Telekommunikation, Medien und Unterhaltung, Einzelhandel, Bildung, Gesundheitswesen und Sonstiges. Banken und verschiedene andere Unternehmen der Finanzbranche nutzen die Technologie des maschinellen Lernens (ML) für zwei wesentliche Zwecke: die Ermittlung wertvoller Dateneinblicke und die Verhinderung von Betrug. Die Einblicke können Investitionsmöglichkeiten aufzeigen oder Anlegern helfen, den richtigen Zeitpunkt für den Handel zu finden.
Akteure auf dem Datenklassifizierungsmarkt konzentrieren sich auf Strategien wie Marktinitiativen, Akquisitionen und Produkteinführungen, um ihre Positionen auf dem Datenklassifizierungsmarkt zu behaupten. Einige Entwicklungen der wichtigsten Akteure auf dem Datenklassifizierungsmarkt sind:
Im März 2020 ermöglicht Netwrix Informationssicherheits- und Governance-Experten, die Kontrolle über vertrauliche, regulierte und geschäftskritische Daten zurückzuerlangen. Das Unternehmen führte Netwrix Data Classification 5.5.2 ein.
Im November 2018 hat Titus, ein führender Anbieter von Datenschutzlösungen, Titus Intelligent Protection eingeführt. Das neue Tool bietet klassifizierungsbasiertes maschinelles Lernen, um das Risiko eines Datenverlusts zu senken.
Regionale Einblicke in den Datenklassifizierungsmarkt
Die regionalen Trends und Faktoren, die den Datenklassifizierungsmarkt während des Prognosezeitraums beeinflussen, wurden von den Analysten von Insight Partners ausführlich erläutert. In diesem Abschnitt werden auch die Marktsegmente und die Geografie des Datenklassifizierungsmarkts in Nordamerika, Europa, im asiatisch-pazifischen Raum, im Nahen Osten und Afrika sowie in Süd- und Mittelamerika erörtert.
- Holen Sie sich die regionalspezifischen Daten für den Datenklassifizierungsmarkt
Umfang des Marktberichts zur Datenklassifizierung
| Berichtsattribut | Details |
|---|---|
| Marktgröße im Jahr 2019 | 568,80 Millionen US-Dollar |
| Marktgröße bis 2027 | 3.577,49 Millionen US-Dollar |
| Globale CAGR (2019 - 2027) | 27,6 % |
| Historische Daten | 2017-2018 |
| Prognosezeitraum | 2020–2027 |
| Abgedeckte Segmente | Nach Lösung
|
| Abgedeckte Regionen und Länder | Nordamerika
|
| Marktführer und wichtige Unternehmensprofile |
|
Marktteilnehmerdichte: Der Einfluss auf die Geschäftsdynamik
Der Markt für Datenklassifizierung wächst rasant, angetrieben durch die steigende Nachfrage der Endnutzer aufgrund von Faktoren wie sich entwickelnden Verbraucherpräferenzen, technologischen Fortschritten und einem größeren Bewusstsein für die Vorteile des Produkts. Mit steigender Nachfrage erweitern Unternehmen ihr Angebot, entwickeln Innovationen, um die Bedürfnisse der Verbraucher zu erfüllen, und nutzen neue Trends, was das Marktwachstum weiter ankurbelt.
Die Marktteilnehmerdichte bezieht sich auf die Verteilung der Firmen oder Unternehmen, die in einem bestimmten Markt oder einer bestimmten Branche tätig sind. Sie gibt an, wie viele Wettbewerber (Marktteilnehmer) in einem bestimmten Marktraum im Verhältnis zu seiner Größe oder seinem gesamten Marktwert präsent sind.
Die wichtigsten auf dem Markt für Datenklassifizierung tätigen Unternehmen sind:
- BOLDON josef
- DATENGUISE
- Google LLC
- Informatica
- Microsoft
Haftungsausschluss : Die oben aufgeführten Unternehmen sind nicht in einer bestimmten Reihenfolge aufgeführt.
- Überblick über die wichtigsten Akteure auf dem Markt für Datenklassifizierung
Markt für Datenklassifizierung – nach Lösungen
- Lösung
- Dienstleistungen
Datenklassifizierungsmarkt – nach Anwendung
- GRC
- Netz
- Mobile
- E-Mail-Schutz
- Sonstiges
Markt für Datenklassifizierung – nach Branchen
- BFSI
- IT und Telekommunikation
- Medien und Unterhaltung
- Einzelhandel
- Ausbildung
- Gesundheitspflege
- Sonstiges
Datenklassifizierungsmarkt – nach Geografie
Nordamerika
- UNS
- Kanada
- Mexiko
Europa
- Frankreich
- Deutschland
- Russland
- Vereinigtes Königreich
- Italien
- Restliches Europa
Asien-Pazifik (APAC)
- China
- Indien
- Japan
- Australien
- Südkorea
- Restlicher Asien-Pazifik-Raum
MEA
- Saudi-Arabien
- Vereinigte Arabische Emirate
- Südafrika
- Rest von MEA
SAM
- Brasilien
- Argentinien
- Rest von SAM
Markt für Datenklassifizierung – Firmenprofile
- James von Boldon
- Google LLC
- Microsoft Corporation
- Open Text Corporation
- DATENGUISE
- Informatica
- Netwrix Corporation
- PKWARE, Inc.
- Titus
- Varonis
- Historische Analyse (2 Jahre), Basisjahr, Prognose (7 Jahre) mit CAGR
- PEST- und SWOT-Analyse
- Marktgröße Wert/Volumen – Global, Regional, Land
- Branche und Wettbewerbsumfeld
- Excel-Datensatz
- Genetic Testing Services Market
- Mobile Phone Insurance Market
- Enzymatic DNA Synthesis Market
- Clear Aligners Market
- Parking Management Market
- Aerosol Paints Market
- Vision Guided Robotics Software Market
- Legal Case Management Software Market
- Transdermal Drug Delivery System Market
- Oxy-fuel Combustion Technology Market

Report Coverage
Revenue forecast, Company Analysis, Industry landscape, Growth factors, and Trends
Segment Covered
This text is related
to segments covered.

Regional Scope
North America, Europe, Asia Pacific, Middle East & Africa, South & Central America
Country Scope
This text is related
to country scope.
Trends and growth analysis reports related to Technology, Media and Telecommunications : READ MORE..
The List of Companies - Global Data Classification Market
- BOLDON JAMES
- DATAGUISE
- Google LLC
- Informatica
- Microsoft
- Netwrix Corporation
- Open Text Corporation
- PKWARE, Inc.
- Symantec Corporation
- Titus
The Insight Partners performs research in 4 major stages: Data Collection & Secondary Research, Primary Research, Data Analysis and Data Triangulation & Final Review.
- Data Collection and Secondary Research:
As a market research and consulting firm operating from a decade, we have published and advised several client across the globe. First step for any study will start with an assessment of currently available data and insights from existing reports. Further, historical and current market information is collected from Investor Presentations, Annual Reports, SEC Filings, etc., and other information related to company’s performance and market positioning are gathered from Paid Databases (Factiva, Hoovers, and Reuters) and various other publications available in public domain.
Several associations trade associates, technical forums, institutes, societies and organization are accessed to gain technical as well as market related insights through their publications such as research papers, blogs and press releases related to the studies are referred to get cues about the market. Further, white papers, journals, magazines, and other news articles published in last 3 years are scrutinized and analyzed to understand the current market trends.
- Primary Research:
The primarily interview analysis comprise of data obtained from industry participants interview and answers to survey questions gathered by in-house primary team.
For primary research, interviews are conducted with industry experts/CEOs/Marketing Managers/VPs/Subject Matter Experts from both demand and supply side to get a 360-degree view of the market. The primary team conducts several interviews based on the complexity of the markets to understand the various market trends and dynamics which makes research more credible and precise.
A typical research interview fulfils the following functions:
- Provides first-hand information on the market size, market trends, growth trends, competitive landscape, and outlook
- Validates and strengthens in-house secondary research findings
- Develops the analysis team’s expertise and market understanding
Primary research involves email interactions and telephone interviews for each market, category, segment, and sub-segment across geographies. The participants who typically take part in such a process include, but are not limited to:
- Industry participants: VPs, business development managers, market intelligence managers and national sales managers
- Outside experts: Valuation experts, research analysts and key opinion leaders specializing in the electronics and semiconductor industry.
Below is the breakup of our primary respondents by company, designation, and region:
Once we receive the confirmation from primary research sources or primary respondents, we finalize the base year market estimation and forecast the data as per the macroeconomic and microeconomic factors assessed during data collection.
- Data Analysis:
Once data is validated through both secondary as well as primary respondents, we finalize the market estimations by hypothesis formulation and factor analysis at regional and country level.
- Macro-Economic Factor Analysis:
We analyse macroeconomic indicators such the gross domestic product (GDP), increase in the demand for goods and services across industries, technological advancement, regional economic growth, governmental policies, the influence of COVID-19, PEST analysis, and other aspects. This analysis aids in setting benchmarks for various nations/regions and approximating market splits. Additionally, the general trend of the aforementioned components aid in determining the market's development possibilities.
- Country Level Data:
Various factors that are especially aligned to the country are taken into account to determine the market size for a certain area and country, including the presence of vendors, such as headquarters and offices, the country's GDP, demand patterns, and industry growth. To comprehend the market dynamics for the nation, a number of growth variables, inhibitors, application areas, and current market trends are researched. The aforementioned elements aid in determining the country's overall market's growth potential.
- Company Profile:
The “Table of Contents” is formulated by listing and analyzing more than 25 - 30 companies operating in the market ecosystem across geographies. However, we profile only 10 companies as a standard practice in our syndicate reports. These 10 companies comprise leading, emerging, and regional players. Nonetheless, our analysis is not restricted to the 10 listed companies, we also analyze other companies present in the market to develop a holistic view and understand the prevailing trends. The “Company Profiles” section in the report covers key facts, business description, products & services, financial information, SWOT analysis, and key developments. The financial information presented is extracted from the annual reports and official documents of the publicly listed companies. Upon collecting the information for the sections of respective companies, we verify them via various primary sources and then compile the data in respective company profiles. The company level information helps us in deriving the base number as well as in forecasting the market size.
- Developing Base Number:
Aggregation of sales statistics (2020-2022) and macro-economic factor, and other secondary and primary research insights are utilized to arrive at base number and related market shares for 2022. The data gaps are identified in this step and relevant market data is analyzed, collected from paid primary interviews or databases. On finalizing the base year market size, forecasts are developed on the basis of macro-economic, industry and market growth factors and company level analysis.
- Data Triangulation and Final Review:
The market findings and base year market size calculations are validated from supply as well as demand side. Demand side validations are based on macro-economic factor analysis and benchmarks for respective regions and countries. In case of supply side validations, revenues of major companies are estimated (in case not available) based on industry benchmark, approximate number of employees, product portfolio, and primary interviews revenues are gathered. Further revenue from target product/service segment is assessed to avoid overshooting of market statistics. In case of heavy deviations between supply and demand side values, all thes steps are repeated to achieve synchronization.
We follow an iterative model, wherein we share our research findings with Subject Matter Experts (SME’s) and Key Opinion Leaders (KOLs) until consensus view of the market is not formulated – this model negates any drastic deviation in the opinions of experts. Only validated and universally acceptable research findings are quoted in our reports.
We have important check points that we use to validate our research findings – which we call – data triangulation, where we validate the information, we generate from secondary sources with primary interviews and then we re-validate with our internal data bases and Subject matter experts. This comprehensive model enables us to deliver high quality, reliable data in shortest possible time.
 Holen Sie sich ein kostenloses Muster für diesen Bericht
Holen Sie sich ein kostenloses Muster für diesen Bericht