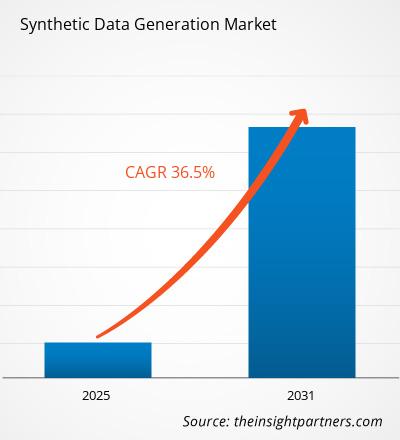
Für den Markt für die Generierung synthetischer Daten wird von 2025 bis 2031 eine durchschnittliche jährliche Wachstumsrate (CAGR) von 36,5 % erwartet, wobei die Marktgröße von XX Millionen US-Dollar im Jahr 2024 auf XX Millionen US-Dollar im Jahr 2031 anwachsen wird.
Der Bericht ist segmentiert nach Angebot (Lösung/Plattform und Services), Datentyp (Tabellen, Text, Bild und Video) und Anwendung (KI/ML-Schulung und -Entwicklung, Testdatenmanagement). Die globale Analyse wird weiter nach Regionen und wichtigen Ländern aufgeschlüsselt. Der Bericht gibt den Wert in USD für die oben genannten Analysen und Segmente an.
Zweck des Berichts
Der Bericht „Markt für synthetische Datengenerierung“ von The Insight Partners beschreibt die aktuelle Marktsituation und das zukünftige Wachstum sowie die wichtigsten Treiber, Herausforderungen und Chancen. Dies bietet verschiedenen Geschäftspartnern Einblicke, beispielsweise:
- Technologieanbieter/-hersteller: Um die sich entwickelnde Marktdynamik zu verstehen und die potenziellen Wachstumschancen zu kennen, können sie fundierte strategische Entscheidungen treffen.
- Investoren: Um eine umfassende Trendanalyse hinsichtlich der Marktwachstumsrate, der finanziellen Marktprognosen und der Chancen entlang der Wertschöpfungskette durchzuführen.
- Regulierungsbehörden: Sie regulieren die Richtlinien und polizeilichen Aktivitäten auf dem Markt mit dem Ziel, Missbrauch zu minimieren, das Vertrauen der Anleger zu wahren und die Integrität und Stabilität des Marktes aufrechtzuerhalten.
Marktsegmentierung für die Generierung synthetischer Daten
Angebot
- Lösung/Plattform und Dienste
Datentyp
- Tabellarisch
- Text
- Bild
- Video
Anwendung
- KI/ML-Schulung und -Entwicklung
- Testdatenmanagement
Geographie
- Nordamerika
- Europa
- Asien-Pazifik
- Naher Osten und Afrika
- Süd- und Mittelamerika
Passen Sie diesen Bericht Ihren Anforderungen an
Sie erhalten kostenlos Anpassungen an jedem Bericht, einschließlich Teilen dieses Berichts oder einer Analyse auf Länderebene, eines Excel-Datenpakets sowie tolle Angebote und Rabatte für Start-ups und Universitäten
Markt für synthetische Datengenerierung: Strategische Einblicke

- Informieren Sie sich über die wichtigsten Markttrends in diesem Bericht.Dieses KOSTENLOSE Beispiel umfasst Datenanalysen, von Markttrends bis hin zu Schätzungen und Prognosen.
Wachstumstreiber auf dem Markt für synthetische Datengenerierung
- Wachsende Nachfrage nach Datenschutz: Synthetische Daten ermöglichen es Unternehmen, Datensätze zu erstellen, ohne die Privatsphäre der Nutzer zu gefährden. Sie bieten eine effektive Lösung, um Datenschutzbedenken auszuräumen, insbesondere in Branchen wie dem Gesundheits- und Finanzwesen, in denen sensible personenbezogene Daten im Spiel sind. Durch die Generierung künstlicher Daten, die reale Daten nachahmen, können Unternehmen KI-Modelle trainieren, ohne echte Identitäten preiszugeben, und so Datenschutzbestimmungen wie die DSGVO einhalten.
- Fortschritte in KI und maschinellem Lernen: Die Fortschritte in KI- und maschinellem Lernen haben die Nachfrage nach synthetischen Daten vorangetrieben. Da große, vielfältige Datensätze zum Trainieren komplexer Modelle benötigt werden, trägt die Generierung synthetischer Daten dazu bei, dem Datenmangel entgegenzuwirken, insbesondere bei Nischen- oder hochspezifischen Anwendungen. Sie beschleunigt die Modellentwicklung, indem sie hochwertige, vielfältige Daten bereitstellt, ohne dass teure oder schwer zugängliche reale Daten erforderlich sind.
- Kostengünstige Datengenerierung: Das Sammeln und Kennzeichnen realer Daten kann teuer und zeitaufwändig sein, insbesondere bei Aufgaben wie autonomem Fahren oder medizinischer Forschung. Die Generierung synthetischer Daten reduziert diese Kosten erheblich. Sie ermöglicht Unternehmen die schnelle und kostengünstige Erstellung großer Datenmengen und ermöglicht so ein schnelleres Trainieren und Testen von Modellen. Dies ist besonders in Bereichen von Vorteil, die kontinuierliche Aktualisierungen oder groß angelegte Simulationen erfordern.
Zukünftige Trends auf dem Markt für die Generierung synthetischer Daten
- Integration mit KI und Deep Learning: Der Trend zur Integration synthetischer Daten in fortschrittliche KI- und Deep-Learning-Modelle nimmt zu. KI-gesteuerte Tools zur Generierung synthetischer Daten werden immer ausgefeilter und können hochwertige, realistische Datensätze erstellen, die auf spezifische Trainingsanforderungen zugeschnitten sind. Da Deep-Learning-Techniken riesige Mengen an gekennzeichneten Daten erfordern, gewinnt die Nutzung synthetischer Daten zum effizienteren Trainieren von Modellen branchenübergreifend an Bedeutung.
- Zunehmende Nutzung synthetischer Daten im Gesundheitswesen: Angesichts von Datenschutzbedenken und verschärften regulatorischen Anforderungen nutzt der Gesundheitssektor zunehmend synthetische Daten für das Training von Machine-Learning-Modellen. Gesundheitsorganisationen nutzen synthetische Datensätze, um Lösungen für medizinische Bildgebung, Arzneimittelforschung und Patientenversorgungsmodelle zu entwickeln und gleichzeitig die Anonymität der Patienten zu gewährleisten. Dieser Trend wird durch den Bedarf an großen Datensätzen vorangetrieben, die die KI-Genauigkeit verbessern können, ohne den Datenschutz zu beeinträchtigen.
- Kooperationen und strategische Partnerschaften: Viele Unternehmen im Markt für synthetische Daten bilden strategische Allianzen, um ihr Angebot zu erweitern. Durch die Zusammenarbeit mit KI-Unternehmen, Forschungseinrichtungen oder Gesundheitsdienstleistern wollen diese Unternehmen das Know-how und die Ressourcen des jeweils anderen nutzen, um Technologien zur Generierung synthetischer Daten voranzutreiben. Solche Partnerschaften tragen zur Entwicklung maßgeschneiderter Lösungen für verschiedene Branchen bei und beschleunigen so die Einführung synthetischer Daten.
Marktchancen für die Generierung synthetischer Daten
- Entwicklung autonomer Fahrzeuge: Die Branche der autonomen Fahrzeuge profitiert von synthetischen Daten zur Simulation verschiedener Fahrszenarien, die in der realen Welt schwierig oder gefährlich nachzubilden sein könnten. Synthetische Daten ermöglichen die Darstellung unterschiedlicher Straßenbedingungen, Wettersituationen und Verkehrsverhaltensweisen, die für das Training und Testen von KI-Systemen in selbstfahrenden Autos unerlässlich sind. Diese Möglichkeit beschleunigt den Entwicklungsprozess und gewährleistet gleichzeitig Sicherheit und Zuverlässigkeit.
- KI- und Machine-Learning-Forschung: Forscher im Bereich KI und Machine Learning können synthetische Daten nutzen, um Algorithmen zu trainieren, wenn reale Daten knapp oder nicht repräsentativ genug sind. In Anwendungen wie der Verarbeitung natürlicher Sprache (NLP) oder der Computervision bieten synthetische Daten die Flexibilität, spezifische Datensätze für Trainingszwecke zu generieren. Dies reduziert die Abhängigkeit von proprietären Daten und eröffnet neue Wege für die akademische und industrielle Forschung.
- Finanzsektor und Betrugserkennung: In der Finanzbranche können synthetische Daten verwendet werden, um Transaktionen, Finanzereignisse oder betrügerische Aktivitäten zu simulieren, ohne sensible Kundeninformationen preiszugeben. Durch das Training von KI-Modellen mit synthetischen Datensätzen können Finanzinstitute ihre Betrugserkennung verbessern, Risiken minimieren und gleichzeitig den Datenschutz gewährleisten. Diese Möglichkeit ermöglicht zudem die Erstellung vielfältigerer Datensätze für bessere Finanzprognosen und Markttrendanalysen.
Regionale Einblicke in den Markt für synthetische Datengenerierung
Die Analysten von Insight Partners haben die regionalen Trends und Faktoren, die den Markt für synthetische Datengenerierung im Prognosezeitraum beeinflussen, ausführlich erläutert. In diesem Abschnitt werden auch die Marktsegmente und die geografische Lage der synthetischen Datengenerierung in Nordamerika, Europa, Asien-Pazifik, dem Nahen Osten und Afrika sowie Süd- und Mittelamerika erörtert.
- Erhalten Sie regionale Daten zum Markt für synthetische Datengenerierung
Umfang des Marktberichts zur Generierung synthetischer Daten
| Berichtsattribut | Details |
|---|---|
| Marktgröße im Jahr 2024 | XX Millionen US-Dollar |
| Marktgröße bis 2031 | XX Millionen US-Dollar |
| Globale CAGR (2025 – 2031) | 36,5 % |
| Historische Daten | 2021-2023 |
| Prognosezeitraum | 2025–2031 |
| Abgedeckte Segmente | Durch das Angebot
|
| Abgedeckte Regionen und Länder | Nordamerika
|
| Marktführer und wichtige Unternehmensprofile |
|
Dichte der Marktteilnehmer bei der Generierung synthetischer Daten: Auswirkungen auf die Geschäftsdynamik verstehen
Der Markt für synthetische Datengenerierung wächst rasant. Dies wird durch die steigende Endverbrauchernachfrage aufgrund veränderter Verbraucherpräferenzen, technologischer Fortschritte und eines stärkeren Bewusstseins für die Produktvorteile vorangetrieben. Mit der steigenden Nachfrage erweitern Unternehmen ihr Angebot, entwickeln Innovationen, um den Verbraucherbedürfnissen gerecht zu werden, und nutzen neue Trends, was das Marktwachstum weiter ankurbelt.
Die Marktteilnehmerdichte beschreibt die Verteilung der in einem bestimmten Markt oder einer bestimmten Branche tätigen Unternehmen. Sie gibt an, wie viele Wettbewerber (Marktteilnehmer) in einem bestimmten Marktraum im Verhältnis zu dessen Größe oder Gesamtmarktwert präsent sind.
Die wichtigsten Unternehmen auf dem Markt für synthetische Datengenerierung sind:
- Microsoft
- IBM
- AWS
- NVIDIA
- OpenAI
Haftungsausschluss : Die oben aufgeführten Unternehmen sind nicht in einer bestimmten Reihenfolge aufgeführt.
- Überblick über die wichtigsten Akteure auf dem Markt für synthetische Datengenerierung
Wichtige Verkaufsargumente
- Umfassende Abdeckung: Der Bericht deckt die Analyse von Produkten, Diensten, Typen und Endbenutzern des Marktes für synthetische Datengenerierung umfassend ab und bietet eine ganzheitliche Landschaft.
- Expertenanalyse: Der Bericht basiert auf dem umfassenden Verständnis von Branchenexperten und Analysten.
- Aktuelle Informationen: Der Bericht gewährleistet Geschäftsrelevanz durch die Berichterstattung über aktuelle Informationen und Datentrends.
- Anpassungsoptionen: Dieser Bericht kann angepasst werden, um den spezifischen Kundenanforderungen gerecht zu werden und die Geschäftsstrategien optimal anzupassen.
Der Forschungsbericht zum Markt für synthetische Datengenerierung kann daher dazu beitragen, die Branchensituation und die Wachstumsaussichten zu entschlüsseln und zu verstehen. Obwohl es einige berechtigte Bedenken geben mag, überwiegen die Vorteile dieses Berichts tendenziell die Nachteile.
- Historische Analyse (2 Jahre), Basisjahr, Prognose (7 Jahre) mit CAGR
- PEST- und SWOT-Analyse
- Marktgröße Wert/Volumen – Global, Regional, Land
- Branche und Wettbewerbsumfeld
- Excel-Datensatz

Report Coverage
Revenue forecast, Company Analysis, Industry landscape, Growth factors, and Trends
Segment Covered
This text is related
to segments covered.

Regional Scope
North America, Europe, Asia Pacific, Middle East & Africa, South & Central America
Country Scope
This text is related
to country scope.
Häufig gestellte Fragen
Some of the customization options available based on the request are an additional 3–5 company profiles and country-specific analysis of 3–5 countries of your choice. Customizations are to be requested/discussed before making final order confirmation# as our team would review the same and check the feasibility
The report can be delivered in PDF/PPT format; we can also share excel dataset based on the request
Increased Adoption of Synthetic Data in Healthcare, Collaborations and Strategic Partnerships, Synthetic Data for Edge and IoT Applications
Growing Demand for Data Privacy, Advancements in AI and Machine Learning, Cost-Effective Data Generation
The global Synthetic Data Generation market is expected to grow at a CAGR of 36.5% during the forecast period 2024 - 2031
Trends and growth analysis reports related to Technology, Media and Telecommunications : READ MORE..
The Insight Partners performs research in 4 major stages: Data Collection & Secondary Research, Primary Research, Data Analysis and Data Triangulation & Final Review.
- Data Collection and Secondary Research:
As a market research and consulting firm operating from a decade, we have published and advised several client across the globe. First step for any study will start with an assessment of currently available data and insights from existing reports. Further, historical and current market information is collected from Investor Presentations, Annual Reports, SEC Filings, etc., and other information related to company’s performance and market positioning are gathered from Paid Databases (Factiva, Hoovers, and Reuters) and various other publications available in public domain.
Several associations trade associates, technical forums, institutes, societies and organization are accessed to gain technical as well as market related insights through their publications such as research papers, blogs and press releases related to the studies are referred to get cues about the market. Further, white papers, journals, magazines, and other news articles published in last 3 years are scrutinized and analyzed to understand the current market trends.
- Primary Research:
The primarily interview analysis comprise of data obtained from industry participants interview and answers to survey questions gathered by in-house primary team.
For primary research, interviews are conducted with industry experts/CEOs/Marketing Managers/VPs/Subject Matter Experts from both demand and supply side to get a 360-degree view of the market. The primary team conducts several interviews based on the complexity of the markets to understand the various market trends and dynamics which makes research more credible and precise.
A typical research interview fulfils the following functions:
- Provides first-hand information on the market size, market trends, growth trends, competitive landscape, and outlook
- Validates and strengthens in-house secondary research findings
- Develops the analysis team’s expertise and market understanding
Primary research involves email interactions and telephone interviews for each market, category, segment, and sub-segment across geographies. The participants who typically take part in such a process include, but are not limited to:
- Industry participants: VPs, business development managers, market intelligence managers and national sales managers
- Outside experts: Valuation experts, research analysts and key opinion leaders specializing in the electronics and semiconductor industry.
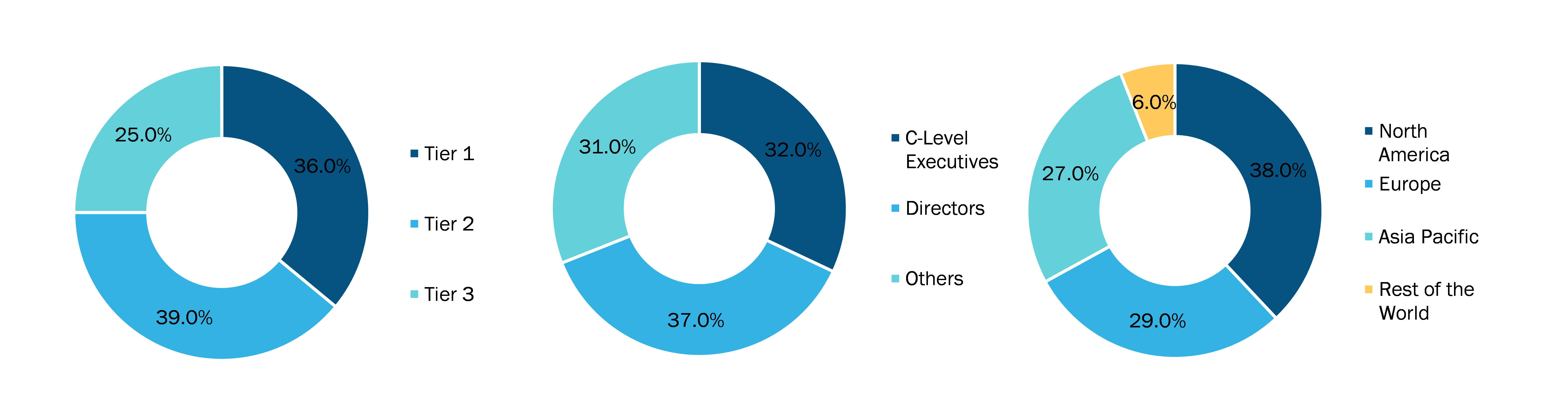
Below is the breakup of our primary respondents by company, designation, and region:
Once we receive the confirmation from primary research sources or primary respondents, we finalize the base year market estimation and forecast the data as per the macroeconomic and microeconomic factors assessed during data collection.
- Data Analysis:
Once data is validated through both secondary as well as primary respondents, we finalize the market estimations by hypothesis formulation and factor analysis at regional and country level.
- Macro-Economic Factor Analysis:
We analyse macroeconomic indicators such the gross domestic product (GDP), increase in the demand for goods and services across industries, technological advancement, regional economic growth, governmental policies, the influence of COVID-19, PEST analysis, and other aspects. This analysis aids in setting benchmarks for various nations/regions and approximating market splits. Additionally, the general trend of the aforementioned components aid in determining the market's development possibilities.
- Country Level Data:
Various factors that are especially aligned to the country are taken into account to determine the market size for a certain area and country, including the presence of vendors, such as headquarters and offices, the country's GDP, demand patterns, and industry growth. To comprehend the market dynamics for the nation, a number of growth variables, inhibitors, application areas, and current market trends are researched. The aforementioned elements aid in determining the country's overall market's growth potential.
- Company Profile:
The “Table of Contents” is formulated by listing and analyzing more than 25 - 30 companies operating in the market ecosystem across geographies. However, we profile only 10 companies as a standard practice in our syndicate reports. These 10 companies comprise leading, emerging, and regional players. Nonetheless, our analysis is not restricted to the 10 listed companies, we also analyze other companies present in the market to develop a holistic view and understand the prevailing trends. The “Company Profiles” section in the report covers key facts, business description, products & services, financial information, SWOT analysis, and key developments. The financial information presented is extracted from the annual reports and official documents of the publicly listed companies. Upon collecting the information for the sections of respective companies, we verify them via various primary sources and then compile the data in respective company profiles. The company level information helps us in deriving the base number as well as in forecasting the market size.
- Developing Base Number:
Aggregation of sales statistics (2020-2022) and macro-economic factor, and other secondary and primary research insights are utilized to arrive at base number and related market shares for 2022. The data gaps are identified in this step and relevant market data is analyzed, collected from paid primary interviews or databases. On finalizing the base year market size, forecasts are developed on the basis of macro-economic, industry and market growth factors and company level analysis.
- Data Triangulation and Final Review:
The market findings and base year market size calculations are validated from supply as well as demand side. Demand side validations are based on macro-economic factor analysis and benchmarks for respective regions and countries. In case of supply side validations, revenues of major companies are estimated (in case not available) based on industry benchmark, approximate number of employees, product portfolio, and primary interviews revenues are gathered. Further revenue from target product/service segment is assessed to avoid overshooting of market statistics. In case of heavy deviations between supply and demand side values, all thes steps are repeated to achieve synchronization.
We follow an iterative model, wherein we share our research findings with Subject Matter Experts (SME’s) and Key Opinion Leaders (KOLs) until consensus view of the market is not formulated – this model negates any drastic deviation in the opinions of experts. Only validated and universally acceptable research findings are quoted in our reports.
We have important check points that we use to validate our research findings – which we call – data triangulation, where we validate the information, we generate from secondary sources with primary interviews and then we re-validate with our internal data bases and Subject matter experts. This comprehensive model enables us to deliver high quality, reliable data in shortest possible time.
 Holen Sie sich ein kostenloses Muster für diesen Bericht
Holen Sie sich ein kostenloses Muster für diesen Bericht