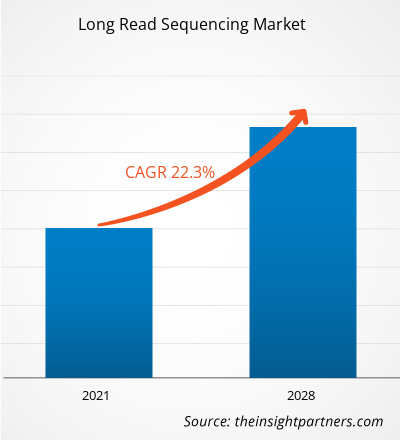
El mercado de secuenciación de lectura larga se valoró en US$ 1.101,15 millones en 2020 y se proyecta que alcance los US$ 5.334,68 millones en 2028; se espera que crezca a una CAGR del 22,3% durante 2021-2028.
La secuencia de lectura larga es una técnica de secuencia de ADN. AD), y depresión, según la investigación gemela. Expone sus vulnerabilidades, como las mutaciones del controlador o la expresión génica . En los últimos años, se han desarrollado y utilizado varias tecnologías de secuenciación de lectura larga. Por ejemplo, Pacific Biosciences desarrolló la secuenciación SMRT , que es uno de los métodos de lectura larga ( PacBio ). La secuenciación de lectura larga se está volviendo más común y los estudios sobre el cáncer basados en datos de lectura larga están creciendo y avanzando con el fin de decodificar genomas de cáncer complejos.
Personalice este informe según sus necesidades
Obtendrá personalización en cualquier informe, sin cargo, incluidas partes de este informe o análisis a nivel de país, paquete de datos de Excel, así como también grandes ofertas y descuentos para empresas emergentes y universidades.
Mercado de secuenciación de lectura larga: perspectivas estratégicas

- Obtenga las principales tendencias clave del mercado de este informe.Esta muestra GRATUITA incluirá análisis de datos, desde tendencias del mercado hasta estimaciones y pronósticos.
Perspectivas del mercado: las ventajas de la secuenciación de lectura larga impulsan el mercado de la secuenciación de lectura larga
Las tecnologías de lectura larga están superando las limitaciones iniciales de precisión y rendimiento y aumentando su aplicación en los campos de la genómica. La secuenciación de lectura larga o secuenciación de tercera generación ofrece varias ventajas sobre la secuenciación de lectura corta. Mientras que los secuenciadores de lectura corta como los instrumentos HiSeq , NovaSeq , NextSeq y MiSeq de Illumina , los modelos MGISEQ y BGISEQ de BGI ; o los secuenciadores Ion Torrent de Thermo Fisher producen lecturas de hasta 600 bases, las tecnologías de secuenciación de lectura larga generan regularmente lecturas de más de 10 kb. Además, las lecturas largas pueden mejorar el ensamblaje de novo , la certeza del mapeo, la identificación de isoformas de transcripción y la detección de variantes estructurales. Además, la secuenciación de lectura larga de moléculas nativas, es decir , ADN y ARN, elimina el sesgo de amplificación al tiempo que preserva las modificaciones de bases. Con el progreso continuo en precisión, rendimiento y reducción de costos, estas capacidades han comenzado a hacer de la secuenciación de lectura larga una opción para una amplia gama de aplicaciones en genómica para organismos modelo y no modelo.
Tecnología: Perspectivas
El mercado global de secuenciación de lectura larga , basado en la tecnología, se segmenta en secuenciación de tiempo real de una sola molécula ( SMRT ), secuenciación de nanoporos y secuenciación de lectura de la genómica de bucle en el segmento de secuencia de tiempo real de una sola molécula ( SMRT ) .
Español : Producto: Según el producto, el mercado global de secuenciación de lectura larga está segmentado en instrumentos, consumibles y servicios. El segmento de instrumentos tuvo la mayor participación del mercado en 2020, y se espera que el segmento de servicios registre la CAGR más alta durante 2021-2028.
Aplicación: Según la aplicación, el mercado global de secuenciación de lectura larga está segmentado en identificación y mapeo fino de variación estructural, secuenciación de repetición en tándem, discriminación de pseudogenes , resolución de fases de alelos, genómica reproductiva, cáncer, secuenciación viral y microbiana, y otros. El segmento de identificación y mapeo fino de variación estructural tuvo la mayor participación del mercado en 2020, y se espera que el segmento de cáncer registre la CAGR más alta de 2021 a 2028.
Flujo de trabajo: Según el flujo de trabajo, el mercado global de secuenciación de lectura larga está segmentado en presecuenciación , secuenciación y análisis de datos. El segmento de secuenciación tuvo la mayor participación del mercado en 2020, y se espera que el mismo segmento registre la CAGR más alta durante 2021-2028.
Usuario final: según el usuario final, el mercado global de secuenciación de lectura larga está segmentado en institutos de investigación académica, hospitales y clínicas, y empresas farmacéuticas y biotecnológicas. El segmento de institutos de investigación académica tuvo la mayor participación del mercado en 2020, y se espera que el mismo segmento registre la CAGR más alta durante 2021-2028.
Perspectivas regionales del mercado de secuenciación de lectura larga
Los analistas de Insight Partners explicaron en detalle las tendencias y los factores regionales que influyen en el mercado de secuenciación de lectura prolongada durante el período de pronóstico. Esta sección también analiza los segmentos y la geografía del mercado de secuenciación de lectura prolongada en América del Norte, Europa, Asia Pacífico, Oriente Medio y África, y América del Sur y Central.
- Obtenga datos regionales específicos para el mercado de secuenciación de lectura larga
Alcance del informe de mercado de secuenciación de lectura larga
| Atributo del informe | Detalles |
|---|---|
| Tamaño del mercado en 2020 | 1.100 millones de dólares estadounidenses |
| Tamaño del mercado en 2028 | 5.330 millones de dólares estadounidenses |
| Tasa de crecimiento anual compuesta (CAGR) global (2020-2028) | 22,3% |
| Datos históricos | 2018-2019 |
| Período de pronóstico | 2021-2028 |
| Segmentos cubiertos | Por tecnología
|
| Regiones y países cubiertos | América del norte
|
| Líderes del mercado y perfiles de empresas clave |
|
Densidad de actores del mercado: comprensión de su impacto en la dinámica empresarial
El mercado de secuenciación de lectura prolongada está creciendo rápidamente, impulsado por la creciente demanda de los usuarios finales debido a factores como la evolución de las preferencias de los consumidores, los avances tecnológicos y una mayor conciencia de los beneficios del producto. A medida que aumenta la demanda, las empresas amplían sus ofertas, innovan para satisfacer las necesidades de los consumidores y aprovechan las tendencias emergentes, lo que impulsa aún más el crecimiento del mercado.
La densidad de actores del mercado se refiere a la distribución de las empresas o firmas que operan dentro de un mercado o industria en particular. Indica cuántos competidores (actores del mercado) están presentes en un espacio de mercado determinado en relación con su tamaño o valor total de mercado.
Las principales empresas que operan en el mercado de secuenciación de lectura larga son:
- Ilumina, Inc.
- Tecnologías de nanoporos de Oxford
- Biocentro TATAA
- PerkinElmer, Inc.
- F. HOFFMANN-LA ROCHE LTD.
Descargo de responsabilidad : Las empresas enumeradas anteriormente no están clasificadas en ningún orden particular.
- Obtenga una descripción general de los principales actores clave del mercado de secuenciación de lectura larga
Los actores que operan en el mercado de secuenciación de lectura larga adoptan estrategias de colaboración y asociación para satisfacer las demandas de los usuarios finales a través de la introducción de ofertas tecnológicamente avanzadas, y estas estrategias respaldan significativamente el crecimiento del mercado.
Por tecnología
- Secuenciación de moléculas individuales en tiempo real (SMRT)
- Secuenciación de nanoporos
- Secuenciación de lectura larga de Loop Genomics
Por producto
- Instrumentos
- Consumibles
- Servicios
Por aplicación
- Identificación y mapeo fino de la variación estructural
- Secuenciación repetida en tándem
- Discriminación pseudogénica
- Resolución de la fase alélica
- Genómica reproductiva
- Cáncer
- Secuenciación viral y microbiana
- Otros
Por flujo de trabajo
- Pre-secuenciación
- Secuenciación
- Análisis de datos
Por el usuario final
- Institutos de investigación académica
- Hospitales y Clínicas
- Empresas farmacéuticas y biotecnológicas
Por geografía
América del norte
- A NOSOTROS
- Canadá
- México
Europa
- Francia
- Alemania
- Italia
- Reino Unido
- España
Asia Pacífico
- Porcelana
- India
- Corea del Sur
- Japón
- Australia
Oriente Medio y África
- Sudáfrica
- Arabia Saudita
- Emiratos Árabes Unidos
América del Sur y Central
- Brasil
- Argentina
Perfiles de empresas
- Tecnologías de nanoporos de Oxford
- Biocentro Tataa
- Illumina, Inc
- Perkinelmer Inc.
- F. Hoffmann-La Roche Ltd.
- Baseclear BV
- Genómica Bionano
- Tecnologías Longas
- Biociencias del Pacífico de California, Inc.
- Compañía Quantapore, Inc.
- Análisis histórico (2 años), año base, pronóstico (7 años) con CAGR
- Análisis PEST y FODA
- Tamaño del mercado Valor/volumen: global, regional, nacional
- Industria y panorama competitivo
- Conjunto de datos de Excel

Report Coverage
Revenue forecast, Company Analysis, Industry landscape, Growth factors, and Trends
Segment Covered
This text is related
to segments covered.

Regional Scope
North America, Europe, Asia Pacific, Middle East & Africa, South & Central America
Country Scope
This text is related
to country scope.
Preguntas frecuentes
The dearth of skilled professionals is the significant factor that will hinder the long read sequencing market growth.
The global long read sequencing market is being driven by factors such as advantages of long read sequencing and increasing prevalence of chronic diseases are likely to offer significant opportunities for the growth of the global long read sequencing market.
Oxford Nanopore Technologies; Tataa Biocenter; Illumina, Inc; Perkinelmer Inc.; F. Hoffmann-La Roche Ltd.; and among others are major companies operating in this market.
Trends and growth analysis reports related to Life Sciences : READ MORE..
The List of Companies - Long Read Sequencing Market
- Illumina, Inc.
- Oxford Nanopore Technologies
- TATAA Biocenter
- PerkinElmer, Inc.
- F. HOFFMANN-LA ROCHE LTD.
- BaseClear B.V.
- Bionano Genomics
- Longas Technologies
- Pacific Biosciences of California, Inc.
- Quantapore, Inc.
The Insight Partners performs research in 4 major stages: Data Collection & Secondary Research, Primary Research, Data Analysis and Data Triangulation & Final Review.
- Data Collection and Secondary Research:
As a market research and consulting firm operating from a decade, we have published and advised several client across the globe. First step for any study will start with an assessment of currently available data and insights from existing reports. Further, historical and current market information is collected from Investor Presentations, Annual Reports, SEC Filings, etc., and other information related to company’s performance and market positioning are gathered from Paid Databases (Factiva, Hoovers, and Reuters) and various other publications available in public domain.
Several associations trade associates, technical forums, institutes, societies and organization are accessed to gain technical as well as market related insights through their publications such as research papers, blogs and press releases related to the studies are referred to get cues about the market. Further, white papers, journals, magazines, and other news articles published in last 3 years are scrutinized and analyzed to understand the current market trends.
- Primary Research:
The primarily interview analysis comprise of data obtained from industry participants interview and answers to survey questions gathered by in-house primary team.
For primary research, interviews are conducted with industry experts/CEOs/Marketing Managers/VPs/Subject Matter Experts from both demand and supply side to get a 360-degree view of the market. The primary team conducts several interviews based on the complexity of the markets to understand the various market trends and dynamics which makes research more credible and precise.
A typical research interview fulfils the following functions:
- Provides first-hand information on the market size, market trends, growth trends, competitive landscape, and outlook
- Validates and strengthens in-house secondary research findings
- Develops the analysis team’s expertise and market understanding
Primary research involves email interactions and telephone interviews for each market, category, segment, and sub-segment across geographies. The participants who typically take part in such a process include, but are not limited to:
- Industry participants: VPs, business development managers, market intelligence managers and national sales managers
- Outside experts: Valuation experts, research analysts and key opinion leaders specializing in the electronics and semiconductor industry.
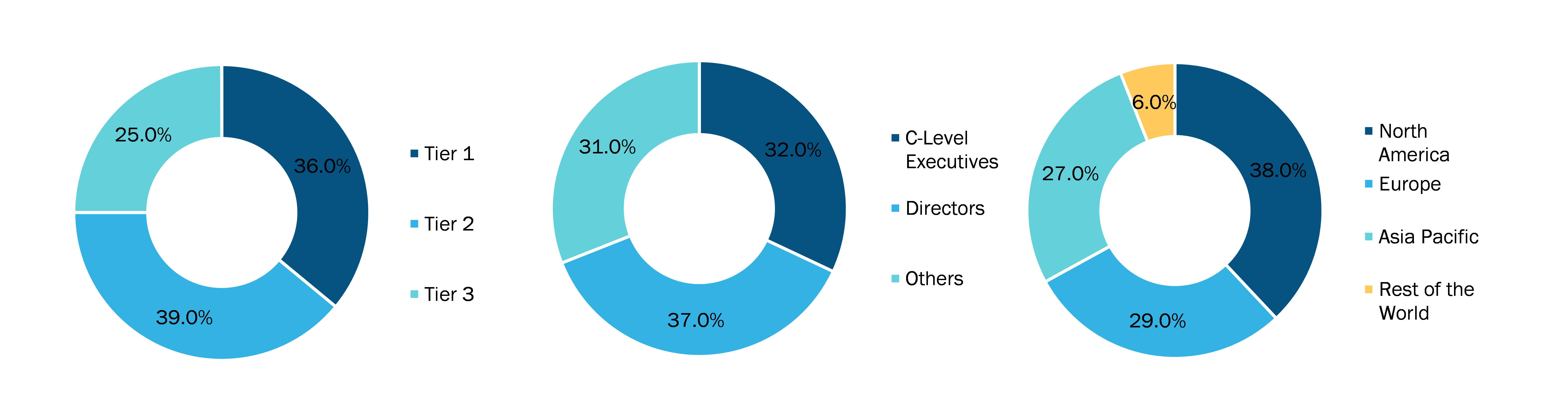
Below is the breakup of our primary respondents by company, designation, and region:
Once we receive the confirmation from primary research sources or primary respondents, we finalize the base year market estimation and forecast the data as per the macroeconomic and microeconomic factors assessed during data collection.
- Data Analysis:
Once data is validated through both secondary as well as primary respondents, we finalize the market estimations by hypothesis formulation and factor analysis at regional and country level.
- Macro-Economic Factor Analysis:
We analyse macroeconomic indicators such the gross domestic product (GDP), increase in the demand for goods and services across industries, technological advancement, regional economic growth, governmental policies, the influence of COVID-19, PEST analysis, and other aspects. This analysis aids in setting benchmarks for various nations/regions and approximating market splits. Additionally, the general trend of the aforementioned components aid in determining the market's development possibilities.
- Country Level Data:
Various factors that are especially aligned to the country are taken into account to determine the market size for a certain area and country, including the presence of vendors, such as headquarters and offices, the country's GDP, demand patterns, and industry growth. To comprehend the market dynamics for the nation, a number of growth variables, inhibitors, application areas, and current market trends are researched. The aforementioned elements aid in determining the country's overall market's growth potential.
- Company Profile:
The “Table of Contents” is formulated by listing and analyzing more than 25 - 30 companies operating in the market ecosystem across geographies. However, we profile only 10 companies as a standard practice in our syndicate reports. These 10 companies comprise leading, emerging, and regional players. Nonetheless, our analysis is not restricted to the 10 listed companies, we also analyze other companies present in the market to develop a holistic view and understand the prevailing trends. The “Company Profiles” section in the report covers key facts, business description, products & services, financial information, SWOT analysis, and key developments. The financial information presented is extracted from the annual reports and official documents of the publicly listed companies. Upon collecting the information for the sections of respective companies, we verify them via various primary sources and then compile the data in respective company profiles. The company level information helps us in deriving the base number as well as in forecasting the market size.
- Developing Base Number:
Aggregation of sales statistics (2020-2022) and macro-economic factor, and other secondary and primary research insights are utilized to arrive at base number and related market shares for 2022. The data gaps are identified in this step and relevant market data is analyzed, collected from paid primary interviews or databases. On finalizing the base year market size, forecasts are developed on the basis of macro-economic, industry and market growth factors and company level analysis.
- Data Triangulation and Final Review:
The market findings and base year market size calculations are validated from supply as well as demand side. Demand side validations are based on macro-economic factor analysis and benchmarks for respective regions and countries. In case of supply side validations, revenues of major companies are estimated (in case not available) based on industry benchmark, approximate number of employees, product portfolio, and primary interviews revenues are gathered. Further revenue from target product/service segment is assessed to avoid overshooting of market statistics. In case of heavy deviations between supply and demand side values, all thes steps are repeated to achieve synchronization.
We follow an iterative model, wherein we share our research findings with Subject Matter Experts (SME’s) and Key Opinion Leaders (KOLs) until consensus view of the market is not formulated – this model negates any drastic deviation in the opinions of experts. Only validated and universally acceptable research findings are quoted in our reports.
We have important check points that we use to validate our research findings – which we call – data triangulation, where we validate the information, we generate from secondary sources with primary interviews and then we re-validate with our internal data bases and Subject matter experts. This comprehensive model enables us to deliver high quality, reliable data in shortest possible time.
 Obtenga una muestra gratuita de este informe
Obtenga una muestra gratuita de este informe