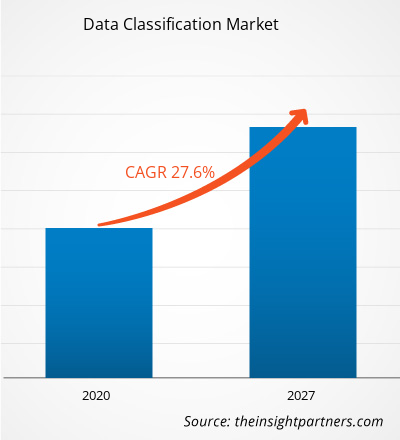
Le marché de la classification des données a été évalué à 568,80 millions USD en 2019 et devrait atteindre 3 577,49 millions USD d'ici 2027. Le marché de la classification des données devrait croître à un TCAC de 27,6 % de 2020 à 2027.
La classification des données est un outil qui classe d'énormes données dans des onglets variés pour en maximiser le plus possible tout en préservant la confidentialité des données confidentielles. La commercialisation des lois sur la protection des données telles que le RGPD et la loi sur la portabilité et la responsabilité de l'assurance maladie (HIPAA) est directement liée à l'impact sur la portée de la classification des données dans le monde entier. La croissance des données d'entreprise et des migrations vers le cloud, l'accélération de l'identification des données personnelles, la menace pour la confidentialité dans les e-mails, l'exploitation de l'apprentissage automatique et la convergence de la gestion et de la protection des données sont parmi les facteurs qui jouent un rôle important dans l'accélération de la portée de la classification des données. La classification des données connaît un essor important dans le monde entier. Le déploiement d'outils de classification des données pour lutter contre les situations de cybermenaces ouvre la voie à la croissance du marché. En outre, l'importance croissante accordée aux lois sur la protection des données par les autorités gouvernementales dans des pays comme le Royaume-Uni, les États-Unis, l'Allemagne et Singapour propulse le taux d'adoption de la classification des données. De plus, l'intégration de technologies sophistiquées telles que l'apprentissage automatique et l'intelligence artificielle dans les outils de classification des données accélère la production et la productivité de l'ensemble de l'entreprise. Par exemple, 40 % des entreprises américaines utilisent le ML pour améliorer leurs stratégies de vente et de marketing, et les banques européennes ont constaté une augmentation des ventes de produits de 10 % et une baisse des taux de désabonnement de 20 % grâce au ML.
Français Le marché de la classification des données est segmenté en composant, application, vertical et géographie. Sur la base du composant, le segment des solutions détenait la plus grande part du marché mondial de la classification des données. La solution de classification des données dérive des contrôles de sécurité appliqués à l'ensemble particulier de données. Sur la base de l'application, le segment de la protection du Web, du mobile et du courrier électronique a dominé le marché mondial de la classification des données en 2019. Avec l'augmentation de l'utilisation du courrier électronique, du mobile et des applications Web pour le transfert de données entre les entreprises et les industries, les outils de protection et de classification des données sont devenus une nécessité. Sur la base du vertical, le segment BFSI a contribué pour une part substantielle en 2019 et devrait continuer à dominer au cours de la période de prévision. Géographiquement, le marché est segmenté en cinq grandes régions : l'Amérique du Nord, l'Europe, l'Asie-Pacifique (APAC), le Moyen-Orient et l'Afrique (MEA) et l'Amérique du Sud (SAM).
Personnalisez ce rapport en fonction de vos besoins
Vous bénéficierez d'une personnalisation gratuite de n'importe quel rapport, y compris de certaines parties de ce rapport, d'une analyse au niveau des pays, d'un pack de données Excel, ainsi que d'offres et de remises exceptionnelles pour les start-ups et les universités.
Marché de la classification des données : perspectives stratégiques

- Obtenez les principales tendances clés du marché de ce rapport.Cet échantillon GRATUIT comprendra une analyse de données, allant des tendances du marché aux estimations et prévisions.
Classification des données Informations sur le marché
Les mandats gouvernementaux dans les pays développés
Les États-Unis, l’Allemagne, le Royaume-Uni et Singapour font partie des pays où le gouvernement a réglementé les entreprises informatiques avec des lois sur le cryptage et la protection des données, ce qui permet aux entreprises technologiques de trouver sur ces marchés des opportunités pour promouvoir leurs services de classification des données. Les gouvernements américain et britannique ont mis en place des systèmes de classification des données à trois niveaux pour le secteur public. Même le gouvernement de Washington est allé plus loin et a établi un système de classification à cinq niveaux, ce qui a été bien accueilli par les défenseurs des données ouvertes de la région en créant un espace potentiel pour les fournisseurs du secteur du domaine. Diverses sociétés de services financiers, telles que les compagnies d’assurance et les banques, sont les principales utilisatrices de solutions de classification des données, car elles doivent gérer de grands volumes d’informations personnelles identifiables (PII) et les réglementations gouvernementales en matière de protection des données.
Informations sur le marché basées sur les composants
Sur la base des composants, le marché de la classification des données est segmenté en solutions et services. Titus, Boldon James, Digital Guardian, Spirion et Netwrix sont quelques-uns des principaux acteurs qui prévalent sur le marché pour répondre aux besoins de protection et de classification des données. Les entreprises proposent un outil complet de classification des données accompagné d'une gamme de services pour garantir le bon fonctionnement de la solution.
Informations sur le marché basées sur les applications
En fonction des applications, le marché de la classification des données est segmenté en gouvernance, risque et conformité, protection du Web, des mobiles et des e-mails, et autres.
Informations sur le marché basées sur la verticale
Le marché de la classification des données est segmenté en fonction des secteurs suivants : BFSI, IT et télécommunications, médias et divertissement, vente au détail, éducation, santé, etc. Les banques et diverses autres sociétés du secteur financier utilisent la technologie Machine Learning (ML) à deux fins essentielles : identifier des informations précieuses sur les données et prévenir la fraude. Ces informations peuvent identifier des opportunités d'investissement ou aider les investisseurs à savoir quand négocier.
Les acteurs opérant sur le marché de la classification des données se concentrent sur des stratégies, telles que des initiatives de marché, des acquisitions et des lancements de produits, pour maintenir leurs positions sur le marché de la classification des données. Voici quelques développements des principaux acteurs du marché de la classification des données :
En mars 2020, Netwrix permet aux professionnels de la sécurité et de la gouvernance de l'information de reprendre le contrôle des données confidentielles, réglementées et critiques pour l'entreprise. La société a lancé Netwrix Data Classification 5.5.2.
En novembre 2018, Titus, leader des solutions de protection des données, a lancé Titus Intelligent Protection. Le nouvel outil fournit un apprentissage automatique basé sur la classification pour réduire le risque de perte de données.
Aperçu régional du marché de la classification des données
Les tendances et facteurs régionaux influençant le marché de la classification des données tout au long de la période de prévision ont été expliqués en détail par les analystes d’Insight Partners. Cette section traite également des segments et de la géographie du marché de la classification des données en Amérique du Nord, en Europe, en Asie-Pacifique, au Moyen-Orient et en Afrique, ainsi qu’en Amérique du Sud et en Amérique centrale.
- Obtenez les données régionales spécifiques pour le marché de la classification des données
Portée du rapport sur le marché de la classification des données
| Attribut de rapport | Détails |
|---|---|
| Taille du marché en 2019 | 568,80 millions de dollars américains |
| Taille du marché d'ici 2027 | 3 577,49 millions de dollars américains |
| Taux de croissance annuel composé mondial (2019-2027) | 27,6% |
| Données historiques | 2017-2018 |
| Période de prévision | 2020-2027 |
| Segments couverts | Par Solution
|
| Régions et pays couverts | Amérique du Nord
|
| Leaders du marché et profils d'entreprises clés |
|
Densité des acteurs du marché : comprendre son impact sur la dynamique des entreprises
Le marché de la classification des données connaît une croissance rapide, tirée par la demande croissante des utilisateurs finaux en raison de facteurs tels que l'évolution des préférences des consommateurs, les avancées technologiques et une plus grande sensibilisation aux avantages du produit. À mesure que la demande augmente, les entreprises élargissent leurs offres, innovent pour répondre aux besoins des consommateurs et capitalisent sur les tendances émergentes, ce qui alimente davantage la croissance du marché.
La densité des acteurs du marché fait référence à la répartition des entreprises ou des sociétés opérant sur un marché ou un secteur particulier. Elle indique le nombre de concurrents (acteurs du marché) présents sur un marché donné par rapport à sa taille ou à sa valeur marchande totale.
Les principales entreprises opérant sur le marché de la classification des données sont :
- BOLDON JAMES
- Guide de données
- Google LLC
- Informatique
- Microsoft
Avis de non-responsabilité : les sociétés répertoriées ci-dessus ne sont pas classées dans un ordre particulier.
- Obtenez un aperçu des principaux acteurs du marché de la classification des données
Marché de la classification des données – par Solutions
- Solution
- Services
Marché de la classification des données – par application
- GRC
- Web
- Mobile
- Protection des e-mails
- Autres
Marché de la classification des données – par secteurs verticaux
- BFSI
- Informatique et Télécom
- Médias et divertissement
- Vente au détail
- Éducation
- Soins de santé
- Autres
Marché de la classification des données – par géographie
Amérique du Nord
- NOUS
- Canada
- Mexique
Europe
- France
- Allemagne
- Russie
- ROYAUME-UNI
- Italie
- Reste de l'Europe
Asie-Pacifique (APAC)
- Chine
- Inde
- Japon
- Australie
- Corée du Sud
- Reste de l'APAC
AEM
- Arabie Saoudite
- Émirats arabes unis
- Afrique du Sud
- Reste de la MEA
SAM
- Brésil
- Argentine
- Reste de SAM
Marché de la classification des données – Profils d’entreprises
- James Boldon
- Google LLC
- Microsoft Corporation
- Société Open Text
- Guide de données
- Informatique
- Société Netwrix
- PKWARE, Inc.
- Tite
- Varonis
- Analyse historique (2 ans), année de base, prévision (7 ans) avec TCAC
- Analyse PEST et SWO
- Taille du marché Valeur / Volume - Mondial, Régional, Pays
- Industrie et paysage concurrentiel
- Ensemble de données Excel

Report Coverage
Revenue forecast, Company Analysis, Industry landscape, Growth factors, and Trends
Segment Covered
This text is related
to segments covered.

Regional Scope
North America, Europe, Asia Pacific, Middle East & Africa, South & Central America
Country Scope
This text is related
to country scope.
Trends and growth analysis reports related to Technology, Media and Telecommunications : READ MORE..
The List of Companies - Global Data Classification Market
- BOLDON JAMES
- DATAGUISE
- Google LLC
- Informatica
- Microsoft
- Netwrix Corporation
- Open Text Corporation
- PKWARE, Inc.
- Symantec Corporation
- Titus
The Insight Partners performs research in 4 major stages: Data Collection & Secondary Research, Primary Research, Data Analysis and Data Triangulation & Final Review.
- Data Collection and Secondary Research:
As a market research and consulting firm operating from a decade, we have published and advised several client across the globe. First step for any study will start with an assessment of currently available data and insights from existing reports. Further, historical and current market information is collected from Investor Presentations, Annual Reports, SEC Filings, etc., and other information related to company’s performance and market positioning are gathered from Paid Databases (Factiva, Hoovers, and Reuters) and various other publications available in public domain.
Several associations trade associates, technical forums, institutes, societies and organization are accessed to gain technical as well as market related insights through their publications such as research papers, blogs and press releases related to the studies are referred to get cues about the market. Further, white papers, journals, magazines, and other news articles published in last 3 years are scrutinized and analyzed to understand the current market trends.
- Primary Research:
The primarily interview analysis comprise of data obtained from industry participants interview and answers to survey questions gathered by in-house primary team.
For primary research, interviews are conducted with industry experts/CEOs/Marketing Managers/VPs/Subject Matter Experts from both demand and supply side to get a 360-degree view of the market. The primary team conducts several interviews based on the complexity of the markets to understand the various market trends and dynamics which makes research more credible and precise.
A typical research interview fulfils the following functions:
- Provides first-hand information on the market size, market trends, growth trends, competitive landscape, and outlook
- Validates and strengthens in-house secondary research findings
- Develops the analysis team’s expertise and market understanding
Primary research involves email interactions and telephone interviews for each market, category, segment, and sub-segment across geographies. The participants who typically take part in such a process include, but are not limited to:
- Industry participants: VPs, business development managers, market intelligence managers and national sales managers
- Outside experts: Valuation experts, research analysts and key opinion leaders specializing in the electronics and semiconductor industry.
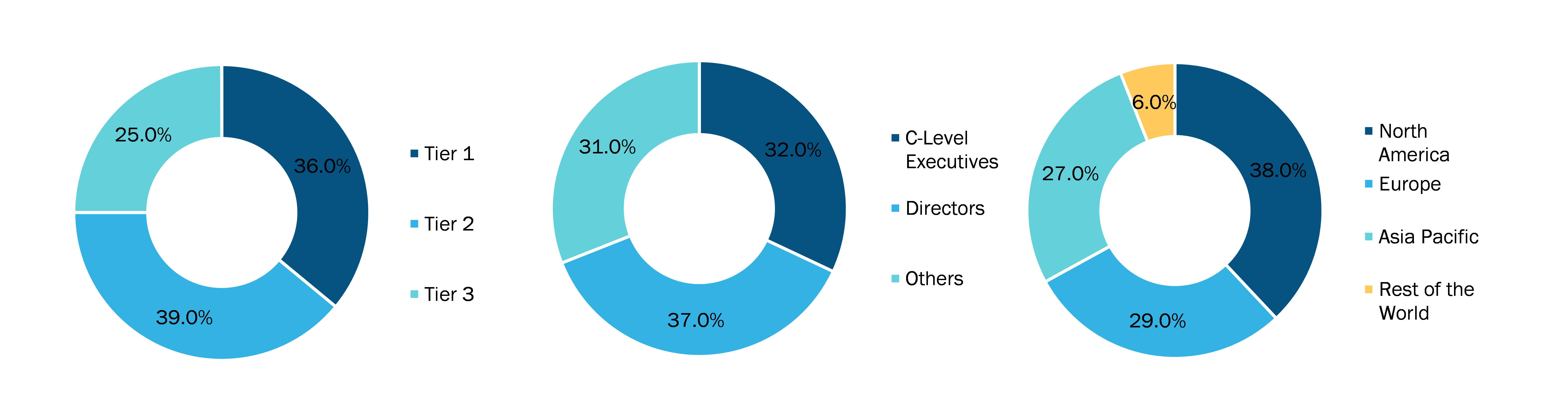
Below is the breakup of our primary respondents by company, designation, and region:
Once we receive the confirmation from primary research sources or primary respondents, we finalize the base year market estimation and forecast the data as per the macroeconomic and microeconomic factors assessed during data collection.
- Data Analysis:
Once data is validated through both secondary as well as primary respondents, we finalize the market estimations by hypothesis formulation and factor analysis at regional and country level.
- Macro-Economic Factor Analysis:
We analyse macroeconomic indicators such the gross domestic product (GDP), increase in the demand for goods and services across industries, technological advancement, regional economic growth, governmental policies, the influence of COVID-19, PEST analysis, and other aspects. This analysis aids in setting benchmarks for various nations/regions and approximating market splits. Additionally, the general trend of the aforementioned components aid in determining the market's development possibilities.
- Country Level Data:
Various factors that are especially aligned to the country are taken into account to determine the market size for a certain area and country, including the presence of vendors, such as headquarters and offices, the country's GDP, demand patterns, and industry growth. To comprehend the market dynamics for the nation, a number of growth variables, inhibitors, application areas, and current market trends are researched. The aforementioned elements aid in determining the country's overall market's growth potential.
- Company Profile:
The “Table of Contents” is formulated by listing and analyzing more than 25 - 30 companies operating in the market ecosystem across geographies. However, we profile only 10 companies as a standard practice in our syndicate reports. These 10 companies comprise leading, emerging, and regional players. Nonetheless, our analysis is not restricted to the 10 listed companies, we also analyze other companies present in the market to develop a holistic view and understand the prevailing trends. The “Company Profiles” section in the report covers key facts, business description, products & services, financial information, SWOT analysis, and key developments. The financial information presented is extracted from the annual reports and official documents of the publicly listed companies. Upon collecting the information for the sections of respective companies, we verify them via various primary sources and then compile the data in respective company profiles. The company level information helps us in deriving the base number as well as in forecasting the market size.
- Developing Base Number:
Aggregation of sales statistics (2020-2022) and macro-economic factor, and other secondary and primary research insights are utilized to arrive at base number and related market shares for 2022. The data gaps are identified in this step and relevant market data is analyzed, collected from paid primary interviews or databases. On finalizing the base year market size, forecasts are developed on the basis of macro-economic, industry and market growth factors and company level analysis.
- Data Triangulation and Final Review:
The market findings and base year market size calculations are validated from supply as well as demand side. Demand side validations are based on macro-economic factor analysis and benchmarks for respective regions and countries. In case of supply side validations, revenues of major companies are estimated (in case not available) based on industry benchmark, approximate number of employees, product portfolio, and primary interviews revenues are gathered. Further revenue from target product/service segment is assessed to avoid overshooting of market statistics. In case of heavy deviations between supply and demand side values, all thes steps are repeated to achieve synchronization.
We follow an iterative model, wherein we share our research findings with Subject Matter Experts (SME’s) and Key Opinion Leaders (KOLs) until consensus view of the market is not formulated – this model negates any drastic deviation in the opinions of experts. Only validated and universally acceptable research findings are quoted in our reports.
We have important check points that we use to validate our research findings – which we call – data triangulation, where we validate the information, we generate from secondary sources with primary interviews and then we re-validate with our internal data bases and Subject matter experts. This comprehensive model enables us to deliver high quality, reliable data in shortest possible time.
 Obtenez un échantillon gratuit pour ce rapport
Obtenez un échantillon gratuit pour ce rapport