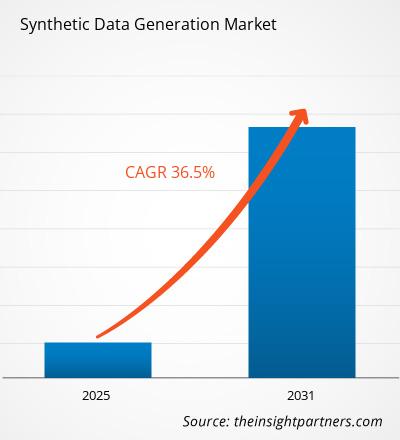
Le marché de la génération de données synthétiques devrait enregistrer un TCAC de 36,5 % de 2025 à 2031, avec une taille de marché passant de XX millions de dollars américains en 2024 à XX millions de dollars américains d'ici 2031.
Le rapport est segmenté par offre (solution/plateforme et services), type de données (tableau, texte, image et vidéo) et application (formation et développement en IA/ML, gestion des données de test). L'analyse globale est ensuite détaillée par région et par principaux pays. Le rapport présente la valeur en USD pour l'analyse et les segments ci-dessus.
Objet du rapport
Le rapport « Marché de la génération de données synthétiques » de The Insight Partners vise à décrire le paysage actuel et la croissance future, les principaux moteurs, les défis et les opportunités. Il fournira des informations aux différents acteurs de l'entreprise, notamment :
- Fournisseurs/fabricants de technologies : pour comprendre l’évolution de la dynamique du marché et connaître les opportunités de croissance potentielles, leur permettant de prendre des décisions stratégiques éclairées.
- Investisseurs : réaliser une analyse complète des tendances concernant le taux de croissance du marché, les projections financières du marché et les opportunités qui existent tout au long de la chaîne de valeur.
- Organismes de réglementation : Réglementer les politiques et les activités de police sur le marché dans le but de minimiser les abus, de préserver la confiance des investisseurs et de maintenir l’intégrité et la stabilité du marché.
Segmentation du marché de la génération de données synthétiques
Offre
- Solution/Plateforme et Services
Type de données
- Tabulaire
- Texte
- Image
- Vidéo
Application
- Formation et développement en IA/ML
- Gestion des données de test
Géographie
- Amérique du Nord
- Europe
- Asie-Pacifique
- Moyen-Orient et Afrique
- Amérique du Sud et Amérique centrale
Personnalisez ce rapport en fonction de vos besoins
Vous bénéficierez d'une personnalisation gratuite de n'importe quel rapport, y compris des parties de ce rapport, ou d'une analyse au niveau des pays, d'un pack de données Excel, ainsi que de superbes offres et réductions pour les start-ups et les universités.
Marché de la génération de données synthétiques : perspectives stratégiques

- Obtenez les principales tendances clés du marché de ce rapport.Cet échantillon GRATUIT comprendra une analyse de données, allant des tendances du marché aux estimations et prévisions.
Moteurs de croissance du marché de la génération de données synthétiques
- Demande croissante de confidentialité des données : les données synthétiques permettent aux organisations de créer des ensembles de données sans compromettre la confidentialité des utilisateurs. Elles constituent une solution efficace pour atténuer les préoccupations en matière de confidentialité, notamment dans des secteurs comme la santé et la finance, où des informations personnelles sensibles sont en jeu. En générant des données artificielles imitant les données réelles, les entreprises peuvent entraîner des modèles d'IA sans exposer les identités réelles, contribuant ainsi à la conformité aux réglementations sur la protection des données telles que le RGPD.
- Progrès de l'IA et de l'apprentissage automatique : Les progrès des technologies d'IA et d'apprentissage automatique ont stimulé la demande de données synthétiques. Face au besoin de vastes ensembles de données diversifiés pour entraîner des modèles complexes, la génération de données synthétiques permet de pallier la rareté des données, notamment pour les applications de niche ou très spécifiques. Elle accélère le développement de modèles en fournissant des données variées et de haute qualité, sans recourir à des données réelles coûteuses ou difficiles d'accès.
- Génération de données rentable : La collecte et l'étiquetage de données réelles peuvent être coûteux et chronophages, notamment pour des tâches comme la conduite autonome ou la recherche médicale. La génération de données synthétiques réduit considérablement ces coûts. Elle permet aux entreprises de créer rapidement et à moindre coût de vastes volumes de données, accélérant ainsi l'apprentissage et les tests des modèles. Ceci est particulièrement avantageux dans les domaines nécessitant des mises à jour continues ou des simulations à grande échelle.
Tendances futures du marché de la génération de données synthétiques
- Intégration avec l'IA et le Deep Learning : L'intégration de données synthétiques à des modèles avancés d'IA et de Deep Learning est en plein essor. Les outils de génération de données synthétiques basés sur l'IA sont de plus en plus sophistiqués et permettent de créer des ensembles de données réalistes et de haute qualité, adaptés à des besoins de formation spécifiques. Les techniques de Deep Learning exigeant des volumes considérables de données étiquetées, l'utilisation de données synthétiques pour entraîner plus efficacement les modèles gagne en popularité dans tous les secteurs.
- Adoption croissante des données synthétiques dans le secteur de la santé : Face aux préoccupations liées à la confidentialité des données et au durcissement des exigences réglementaires, le secteur de la santé adopte de plus en plus de données synthétiques pour l'entraînement des modèles d'apprentissage automatique. Les établissements de santé exploitent ces données synthétiques pour développer des solutions d'imagerie médicale, de découverte de médicaments et de modèles de soins aux patients, tout en garantissant l'anonymat des patients. Cette tendance est alimentée par le besoin de vastes ensembles de données capables d'améliorer la précision de l'IA sans compromettre la confidentialité.
- Collaborations et partenariats stratégiques : De nombreuses entreprises du marché des données synthétiques forment des alliances stratégiques pour enrichir leurs offres. En collaborant avec des entreprises d'IA, des instituts de recherche ou des prestataires de soins de santé, ces entreprises cherchent à tirer parti de leur expertise et de leurs ressources respectives pour faire progresser les technologies de génération de données synthétiques. Ces partenariats contribuent au développement de solutions plus adaptées à divers secteurs, accélérant ainsi l'adoption des données synthétiques.
Opportunités de marché pour la génération de données synthétiques
- Développement de véhicules autonomes : L'industrie des véhicules autonomes tire profit des données synthétiques pour simuler divers scénarios de conduite, parfois difficiles ou dangereux à reproduire en conditions réelles. Ces données permettent de reproduire des conditions routières, météorologiques et des comportements de circulation variés, essentiels à l'entraînement et aux tests des systèmes d'IA embarqués dans les voitures autonomes. Cette opportunité contribue à accélérer le processus de développement tout en garantissant sécurité et fiabilité.
- Recherche en IA et en apprentissage automatique : Les chercheurs en IA et en apprentissage automatique peuvent exploiter les données synthétiques pour entraîner des algorithmes lorsque les données réelles sont rares ou insuffisamment représentatives. Dans des applications comme le traitement automatique du langage naturel (TALN) ou la vision par ordinateur, les données synthétiques offrent la flexibilité nécessaire pour générer des ensembles de données spécifiques à des fins d'entraînement, réduisant ainsi la dépendance aux données propriétaires et ouvrant de nouvelles perspectives à la recherche universitaire et industrielle.
- Secteur financier et détection des fraudes : Dans le secteur financier, les données synthétiques permettent de simuler des transactions, des événements financiers ou des activités frauduleuses sans exposer les informations sensibles des clients. En entraînant des modèles d'IA sur des ensembles de données synthétiques, les institutions financières peuvent améliorer leurs capacités de détection des fraudes et atténuer les risques tout en garantissant la confidentialité des données. Cette opportunité permet également de créer des ensembles de données plus diversifiés pour améliorer les prévisions financières et l'analyse des tendances du marché.
Aperçu régional du marché de la génération de données synthétiques
Les tendances et facteurs régionaux influençant le marché de la génération de données synthétiques tout au long de la période de prévision ont été analysés en détail par les analystes d'Insight Partners. Cette section aborde également les segments et la géographie du marché de la génération de données synthétiques en Amérique du Nord, en Europe, en Asie-Pacifique, au Moyen-Orient et en Afrique, ainsi qu'en Amérique du Sud et en Amérique centrale.
- Obtenez les données régionales spécifiques au marché de la génération de données synthétiques
Portée du rapport sur le marché de la génération de données synthétiques
| Attribut de rapport | Détails |
|---|---|
| Taille du marché en 2024 | XX millions de dollars américains |
| Taille du marché d'ici 2031 | XX millions de dollars américains |
| TCAC mondial (2025 - 2031) | 36,5% |
| Données historiques | 2021-2023 |
| Période de prévision | 2025-2031 |
| Segments couverts | En offrant
|
| Régions et pays couverts | Amérique du Nord
|
| Leaders du marché et profils d'entreprises clés |
|
Densité des acteurs du marché de la génération de données synthétiques : comprendre son impact sur la dynamique des entreprises
Le marché de la génération de données synthétiques connaît une croissance rapide, portée par une demande croissante des utilisateurs finaux, due à des facteurs tels que l'évolution des préférences des consommateurs, les avancées technologiques et une meilleure connaissance des avantages du produit. Face à cette demande croissante, les entreprises élargissent leur offre, innovent pour répondre aux besoins des consommateurs et capitalisent sur les nouvelles tendances, ce qui alimente la croissance du marché.
La densité des acteurs du marché désigne la répartition des entreprises opérant sur un marché ou un secteur particulier. Elle indique le nombre de concurrents (acteurs) présents sur un marché donné par rapport à sa taille ou à sa valeur marchande totale.
Les principales entreprises opérant sur le marché de la génération de données synthétiques sont :
- Microsoft
- IBM
- AWS
- NVIDIA
- OpenAI
Avertissement : Les entreprises répertoriées ci-dessus ne sont pas classées dans un ordre particulier.
- Obtenez un aperçu des principaux acteurs du marché de la génération de données synthétiques
Principaux arguments de vente
- Couverture complète : Le rapport couvre de manière exhaustive l’analyse des produits, des services, des types et des utilisateurs finaux du marché de la génération de données synthétiques, offrant un paysage holistique.
- Analyse d’experts : Le rapport est compilé sur la base d’une compréhension approfondie des experts et analystes du secteur.
- Informations à jour : Le rapport garantit la pertinence commerciale en raison de sa couverture des informations récentes et des tendances des données.
- Options de personnalisation : ce rapport peut être personnalisé pour répondre aux exigences spécifiques des clients et s'adapter de manière appropriée aux stratégies commerciales.
Le rapport de recherche sur le marché de la génération de données synthétiques peut donc contribuer à éclairer et à comprendre le contexte et les perspectives de croissance du secteur. Malgré quelques inquiétudes légitimes, les avantages globaux de ce rapport l'emportent généralement sur ses inconvénients.
- Analyse historique (2 ans), année de base, prévision (7 ans) avec TCAC
- Analyse PEST et SWO
- Taille du marché Valeur / Volume - Mondial, Régional, Pays
- Industrie et paysage concurrentiel
- Ensemble de données Excel

Report Coverage
Revenue forecast, Company Analysis, Industry landscape, Growth factors, and Trends
Segment Covered
This text is related
to segments covered.

Regional Scope
North America, Europe, Asia Pacific, Middle East & Africa, South & Central America
Country Scope
This text is related
to country scope.
Questions fréquemment posées
Some of the customization options available based on the request are an additional 3–5 company profiles and country-specific analysis of 3–5 countries of your choice. Customizations are to be requested/discussed before making final order confirmation# as our team would review the same and check the feasibility
The report can be delivered in PDF/PPT format; we can also share excel dataset based on the request
Increased Adoption of Synthetic Data in Healthcare, Collaborations and Strategic Partnerships, Synthetic Data for Edge and IoT Applications
Growing Demand for Data Privacy, Advancements in AI and Machine Learning, Cost-Effective Data Generation
The global Synthetic Data Generation market is expected to grow at a CAGR of 36.5% during the forecast period 2024 - 2031
Trends and growth analysis reports related to Technology, Media and Telecommunications : READ MORE..
The Insight Partners performs research in 4 major stages: Data Collection & Secondary Research, Primary Research, Data Analysis and Data Triangulation & Final Review.
- Data Collection and Secondary Research:
As a market research and consulting firm operating from a decade, we have published and advised several client across the globe. First step for any study will start with an assessment of currently available data and insights from existing reports. Further, historical and current market information is collected from Investor Presentations, Annual Reports, SEC Filings, etc., and other information related to company’s performance and market positioning are gathered from Paid Databases (Factiva, Hoovers, and Reuters) and various other publications available in public domain.
Several associations trade associates, technical forums, institutes, societies and organization are accessed to gain technical as well as market related insights through their publications such as research papers, blogs and press releases related to the studies are referred to get cues about the market. Further, white papers, journals, magazines, and other news articles published in last 3 years are scrutinized and analyzed to understand the current market trends.
- Primary Research:
The primarily interview analysis comprise of data obtained from industry participants interview and answers to survey questions gathered by in-house primary team.
For primary research, interviews are conducted with industry experts/CEOs/Marketing Managers/VPs/Subject Matter Experts from both demand and supply side to get a 360-degree view of the market. The primary team conducts several interviews based on the complexity of the markets to understand the various market trends and dynamics which makes research more credible and precise.
A typical research interview fulfils the following functions:
- Provides first-hand information on the market size, market trends, growth trends, competitive landscape, and outlook
- Validates and strengthens in-house secondary research findings
- Develops the analysis team’s expertise and market understanding
Primary research involves email interactions and telephone interviews for each market, category, segment, and sub-segment across geographies. The participants who typically take part in such a process include, but are not limited to:
- Industry participants: VPs, business development managers, market intelligence managers and national sales managers
- Outside experts: Valuation experts, research analysts and key opinion leaders specializing in the electronics and semiconductor industry.
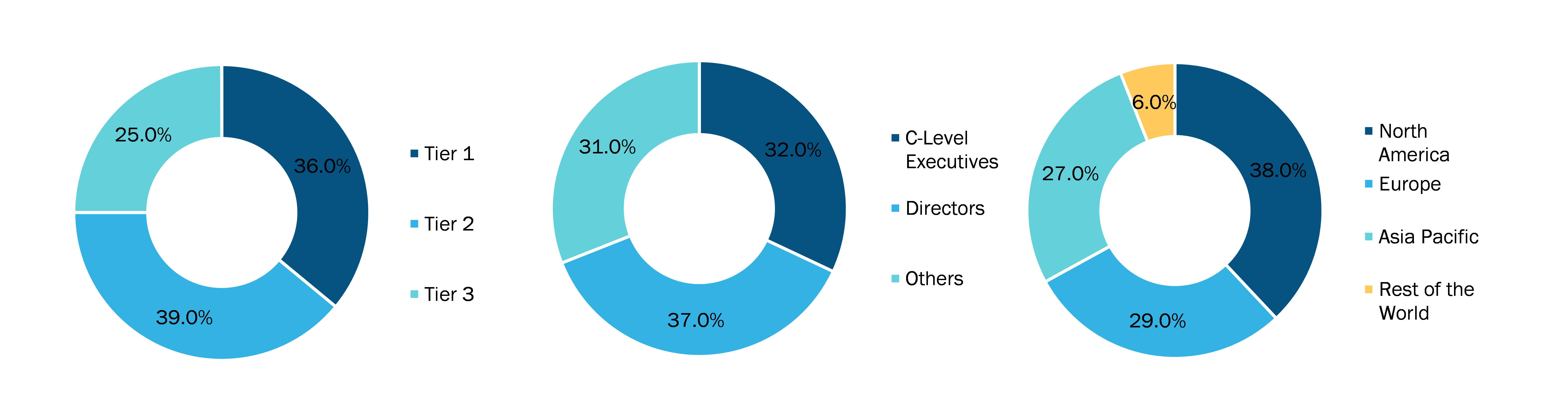
Below is the breakup of our primary respondents by company, designation, and region:
Once we receive the confirmation from primary research sources or primary respondents, we finalize the base year market estimation and forecast the data as per the macroeconomic and microeconomic factors assessed during data collection.
- Data Analysis:
Once data is validated through both secondary as well as primary respondents, we finalize the market estimations by hypothesis formulation and factor analysis at regional and country level.
- Macro-Economic Factor Analysis:
We analyse macroeconomic indicators such the gross domestic product (GDP), increase in the demand for goods and services across industries, technological advancement, regional economic growth, governmental policies, the influence of COVID-19, PEST analysis, and other aspects. This analysis aids in setting benchmarks for various nations/regions and approximating market splits. Additionally, the general trend of the aforementioned components aid in determining the market's development possibilities.
- Country Level Data:
Various factors that are especially aligned to the country are taken into account to determine the market size for a certain area and country, including the presence of vendors, such as headquarters and offices, the country's GDP, demand patterns, and industry growth. To comprehend the market dynamics for the nation, a number of growth variables, inhibitors, application areas, and current market trends are researched. The aforementioned elements aid in determining the country's overall market's growth potential.
- Company Profile:
The “Table of Contents” is formulated by listing and analyzing more than 25 - 30 companies operating in the market ecosystem across geographies. However, we profile only 10 companies as a standard practice in our syndicate reports. These 10 companies comprise leading, emerging, and regional players. Nonetheless, our analysis is not restricted to the 10 listed companies, we also analyze other companies present in the market to develop a holistic view and understand the prevailing trends. The “Company Profiles” section in the report covers key facts, business description, products & services, financial information, SWOT analysis, and key developments. The financial information presented is extracted from the annual reports and official documents of the publicly listed companies. Upon collecting the information for the sections of respective companies, we verify them via various primary sources and then compile the data in respective company profiles. The company level information helps us in deriving the base number as well as in forecasting the market size.
- Developing Base Number:
Aggregation of sales statistics (2020-2022) and macro-economic factor, and other secondary and primary research insights are utilized to arrive at base number and related market shares for 2022. The data gaps are identified in this step and relevant market data is analyzed, collected from paid primary interviews or databases. On finalizing the base year market size, forecasts are developed on the basis of macro-economic, industry and market growth factors and company level analysis.
- Data Triangulation and Final Review:
The market findings and base year market size calculations are validated from supply as well as demand side. Demand side validations are based on macro-economic factor analysis and benchmarks for respective regions and countries. In case of supply side validations, revenues of major companies are estimated (in case not available) based on industry benchmark, approximate number of employees, product portfolio, and primary interviews revenues are gathered. Further revenue from target product/service segment is assessed to avoid overshooting of market statistics. In case of heavy deviations between supply and demand side values, all thes steps are repeated to achieve synchronization.
We follow an iterative model, wherein we share our research findings with Subject Matter Experts (SME’s) and Key Opinion Leaders (KOLs) until consensus view of the market is not formulated – this model negates any drastic deviation in the opinions of experts. Only validated and universally acceptable research findings are quoted in our reports.
We have important check points that we use to validate our research findings – which we call – data triangulation, where we validate the information, we generate from secondary sources with primary interviews and then we re-validate with our internal data bases and Subject matter experts. This comprehensive model enables us to deliver high quality, reliable data in shortest possible time.
 Obtenez un échantillon gratuit pour ce rapport
Obtenez un échantillon gratuit pour ce rapport