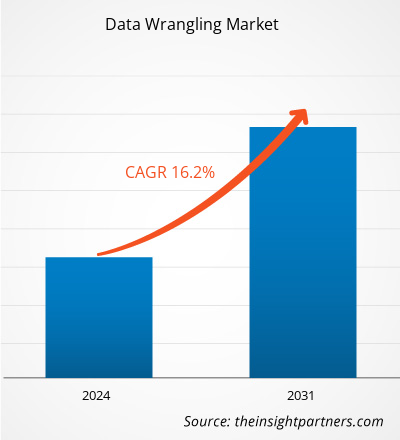
Si prevede che le dimensioni del mercato globale del data wrangling cresceranno da 3,42 miliardi di dollari nel 2023 a 11,37 miliardi di dollari entro il 2031; si prevede che si espanderà a un CAGR del 16,2% dal 2024 al 2031. I crescenti progressi tecnologici come l'intelligenza artificiale e le tecnologie di apprendimento automatico rimarranno probabilmente tendenze chiave del mercato del data wrangling.
Analisi di mercato del data wrangling
La crescente quantità e velocità dei dati nelle aziende sta spingendo in avanti il settore del data wrangling. Le aziende necessitano di strumenti e tecnologie per analizzare e gestire in modo efficiente quantità crescenti di dati.
Panoramica del mercato del Data Wrangling
Il data wrangling è il processo di preparazione e organizzazione dei dati grezzi in modo tale che sia più semplice analizzarli ed estrarre informazioni utili. Comporta la pulizia e la riformattazione dei dati, nonché l'integrazione con nuove informazioni, in modo che possano essere utilizzati in modo efficiente per il processo decisionale. Il data wrangling semplifica e fa risparmiare tempo traducendo set di dati complicati in un formato coerente e ripetibile, consentendo alle organizzazioni di fare scelte più consapevoli con maggiore efficienza.
Personalizza questo report in base alle tue esigenze
Riceverai la personalizzazione gratuita di qualsiasi report, comprese parti di questo report, o analisi a livello nazionale, pacchetto dati Excel, oltre a usufruire di grandi offerte e sconti per start-up e università
Mercato del Data Wrangling: approfondimenti strategici

- Scopri le principali tendenze di mercato in questo rapporto.Questo campione GRATUITO includerà analisi di dati che spaziano dalle tendenze di mercato alle stime e alle previsioni.
Driver e opportunità di mercato per il Data Wrangling
Aumento del volume e della velocità dei dati per favorire il mercato
La crescente quantità e velocità dei dati nelle aziende sta spingendo in avanti il settore del data wrangling. Man mano che le organizzazioni creano e raccolgono più dati, aumenta la domanda di strumenti e tecnologie in grado di gestirli e amministrarli in modo efficiente. La velocità dei dati è correlata alla rapidità con cui vengono creati e spostati. Con l'avvento dell'Internet of Things (IoT) e di altri dispositivi connessi, i dati fluiscono nelle organizzazioni a una velocità senza precedenti e devono essere elaborati in modo tempestivo. Le organizzazioni vogliono strumenti e tecnologie in grado di gestire e analizzare i dati in tempo reale mentre vengono creati, consentendo loro di fare scelte più tempestive in base ai fatti attuali.
Crescita delle soluzioni di Edge Computing
L'edge computing è una piattaforma di elaborazione distribuita che collega le applicazioni aziendali a fonti di dati come dispositivi IoT o server edge locali. Comporta l'elaborazione dei dati più vicino al luogo in cui sono stati creati anziché dipendere solo da data center centralizzati o dal cloud. Questa tecnica presenta vari vantaggi, tra cui informazioni più rapide, tempi di risposta più rapidi, maggiore disponibilità di larghezza di banda e minore latenza. L'ascesa dell'edge computing ha favorito l'espansione del settore del data wrangling. L'edge computing crea molti dati che devono essere gestiti ed esaminati. Ciò aumenta la domanda di strumenti di data wrangling, che vengono utilizzati per pulire, manipolare e preparare i dati per ulteriori analisi.
Analisi della segmentazione del rapporto di mercato di Data Wrangling
I segmenti chiave che hanno contribuito alla derivazione dell'analisi di mercato del data wrangling sono i componenti, la funzione aziendale, le dimensioni dell'organizzazione e il settore verticale.
- In base al componente, il mercato è diviso in strumenti e servizi. Il segmento degli strumenti ha detenuto una quota di mercato maggiore nel 2023.
- In termini di funzione aziendale, il mercato è suddiviso in finanza, marketing e vendite, operazioni, risorse umane e legale. Il segmento finanziario ha detenuto una quota di mercato maggiore nel 2023.
- In base alle dimensioni dell'organizzazione, il mercato è diviso in PMI e grandi imprese. Il segmento delle grandi imprese ha detenuto una quota di mercato maggiore nel 2023.
- In base al settore verticale, il mercato è diviso in BFSI, governo, sanità, IT e telecomunicazioni, produzione, vendita al dettaglio e altri. Il segmento BFSI ha detenuto una quota di mercato maggiore nel 2023.
Analisi della quota di mercato del Data Wrangling per area geografica
L'ambito geografico del report di mercato Data Wrangling è suddiviso principalmente in cinque regioni: Nord America, Asia Pacifico, Europa, Medio Oriente e Africa e Sud America/Sud e Centro America. Il Nord America ha dominato il mercato del data wrangling nel 2023. La crescente digitalizzazione di aziende e organizzazioni nel Nord America è un fattore determinante per il mercato del data wrangling. Poiché le aziende generano e raccolgono grandi volumi di dati, la necessità di strumenti e software efficaci per il data wrangling diventa cruciale. Inoltre, la crescente domanda di analisi di big data nel Nord America è un altro fattore che guida la crescita del mercato del data wrangling. Il data wrangling svolge un ruolo fondamentale nella preparazione e nella pulizia dei dati per l'analisi, consentendo alle organizzazioni di ricavare informazioni preziose dai propri dati.
Approfondimenti regionali sul mercato del Data Wrangling
Le tendenze regionali e i fattori che influenzano il Data Wrangling Market durante il periodo di previsione sono stati ampiamente spiegati dagli analisti di Insight Partners. Questa sezione discute anche i segmenti e la geografia del Data Wrangling Market in Nord America, Europa, Asia Pacifico, Medio Oriente e Africa e Sud e Centro America.
- Ottieni i dati specifici regionali per il mercato Data Wrangling
Ambito del rapporto di mercato sul Data Wrangling
| Attributo del report | Dettagli |
|---|---|
| Dimensioni del mercato nel 2023 | 3,42 miliardi di dollari USA |
| Dimensioni del mercato entro il 2031 | 11,37 miliardi di dollari USA |
| CAGR globale (2024 - 2031)CAGR (2024 - 2031) | 16,2% |
| Dati storici | 2021-2022 |
| Periodo di previsione | 2024-2031 |
| Segmenti coperti | Per componente
|
| Regioni e Paesi coperti | America del Nord
|
| Leader di mercato e profili aziendali chiave |
|
Densità degli attori del mercato: comprendere il suo impatto sulle dinamiche aziendali
Il mercato del Data Wrangling Market sta crescendo rapidamente, spinto dalla crescente domanda degli utenti finali dovuta a fattori quali l'evoluzione delle preferenze dei consumatori, i progressi tecnologici e una maggiore consapevolezza dei vantaggi del prodotto. Con l'aumento della domanda, le aziende stanno ampliando le loro offerte, innovando per soddisfare le esigenze dei consumatori e capitalizzando sulle tendenze emergenti, il che alimenta ulteriormente la crescita del mercato.
La densità degli operatori di mercato si riferisce alla distribuzione di aziende o società che operano in un particolare mercato o settore. Indica quanti concorrenti (operatori di mercato) sono presenti in un dato spazio di mercato in relazione alle sue dimensioni o al valore di mercato totale.
Le principali aziende che operano nel mercato del Data Wrangling sono:
- BRILLO
- Azienda AG
- Paxata, Inc.
- Trifatto
- Alterige
- Altair Engineering, Inc.
Disclaimer : le aziende elencate sopra non sono classificate secondo un ordine particolare.
- Ottieni una panoramica dei principali attori del mercato Data Wrangling
Notizie di mercato e sviluppi recenti del Data Wrangling
Il mercato del data wrangling viene valutato raccogliendo dati qualitativi e quantitativi dopo la ricerca primaria e secondaria, che include importanti pubblicazioni aziendali, dati associativi e database. Di seguito è riportato un elenco degli sviluppi nel mercato:
- Ad aprile 2021, Trifacta ha introdotto uno strumento avanzato che consente ai clienti di utilizzare senza problemi i propri dati all'interno di Google BigQuery, introducendo anche due nuove integrazioni volte a migliorare i processi di preparazione dei dati.
(Fonte: Trifacta, Comunicato stampa, 2021)
Copertura e risultati del rapporto di mercato sul Data Wrangling
Il rapporto "Dimensioni e previsioni del mercato del Data Wrangling (2021-2031)" fornisce un'analisi dettagliata del mercato che copre le seguenti aree:
- Dimensioni del mercato e previsioni a livello globale, regionale e nazionale per tutti i segmenti di mercato chiave coperti dall'ambito
- Dinamiche di mercato come fattori trainanti, vincoli e opportunità chiave
- Principali tendenze future
- Analisi dettagliata delle cinque forze PEST/Porter e SWOT
- Analisi di mercato globale e regionale che copre le principali tendenze di mercato, i principali attori, le normative e gli sviluppi recenti del mercato
- Analisi del panorama industriale e della concorrenza che copre la concentrazione del mercato, l'analisi della mappa di calore, i principali attori e gli sviluppi recenti
- Profili aziendali dettagliati
- Analisi storica (2 anni), anno base, previsione (7 anni) con CAGR
- Analisi PEST e SWOT
- Valore/volume delle dimensioni del mercato - Globale, regionale, nazionale
- Industria e panorama competitivo
- Set di dati Excel
- Virtual Production Market
- Bioremediation Technology and Services Market
- Aerosol Paints Market
- Electronic Shelf Label Market
- Intraoperative Neuromonitoring Market
- Digital Pathology Market
- Wheat Protein Market
- Batter and Breader Premixes Market
- Excimer & Femtosecond Ophthalmic Lasers Market
- Machine Condition Monitoring Market

Report Coverage
Revenue forecast, Company Analysis, Industry landscape, Growth factors, and Trends
Segment Covered
This text is related
to segments covered.

Regional Scope
North America, Europe, Asia Pacific, Middle East & Africa, South & Central America
Country Scope
This text is related
to country scope.
Domande frequenti
The global data wrangling market is expected to reach US$ 11.37 billion by 2031.
The key players holding the majority of shares in the global data wrangling market are BRILLIO, ONEDOT AG, Paxata, Inc., Trifacta, and Alteryx.
The growing technological advancements such as AI and machine learning technologies are likely to remain a key data wrangling market trends.
The growth of the data wrangling market is fuelled by the increasing volume and velocity of data across organizations.
The data wrangling market size is expected to grow from US$ 3.42 billion in 2023 to US$ 11.37 billion by 2031; it is anticipated to expand at a CAGR of 16.2% from 2024 to 2031.
Trends and growth analysis reports related to Technology, Media and Telecommunications : READ MORE..
The Insight Partners performs research in 4 major stages: Data Collection & Secondary Research, Primary Research, Data Analysis and Data Triangulation & Final Review.
- Data Collection and Secondary Research:
As a market research and consulting firm operating from a decade, we have published and advised several client across the globe. First step for any study will start with an assessment of currently available data and insights from existing reports. Further, historical and current market information is collected from Investor Presentations, Annual Reports, SEC Filings, etc., and other information related to company’s performance and market positioning are gathered from Paid Databases (Factiva, Hoovers, and Reuters) and various other publications available in public domain.
Several associations trade associates, technical forums, institutes, societies and organization are accessed to gain technical as well as market related insights through their publications such as research papers, blogs and press releases related to the studies are referred to get cues about the market. Further, white papers, journals, magazines, and other news articles published in last 3 years are scrutinized and analyzed to understand the current market trends.
- Primary Research:
The primarily interview analysis comprise of data obtained from industry participants interview and answers to survey questions gathered by in-house primary team.
For primary research, interviews are conducted with industry experts/CEOs/Marketing Managers/VPs/Subject Matter Experts from both demand and supply side to get a 360-degree view of the market. The primary team conducts several interviews based on the complexity of the markets to understand the various market trends and dynamics which makes research more credible and precise.
A typical research interview fulfils the following functions:
- Provides first-hand information on the market size, market trends, growth trends, competitive landscape, and outlook
- Validates and strengthens in-house secondary research findings
- Develops the analysis team’s expertise and market understanding
Primary research involves email interactions and telephone interviews for each market, category, segment, and sub-segment across geographies. The participants who typically take part in such a process include, but are not limited to:
- Industry participants: VPs, business development managers, market intelligence managers and national sales managers
- Outside experts: Valuation experts, research analysts and key opinion leaders specializing in the electronics and semiconductor industry.
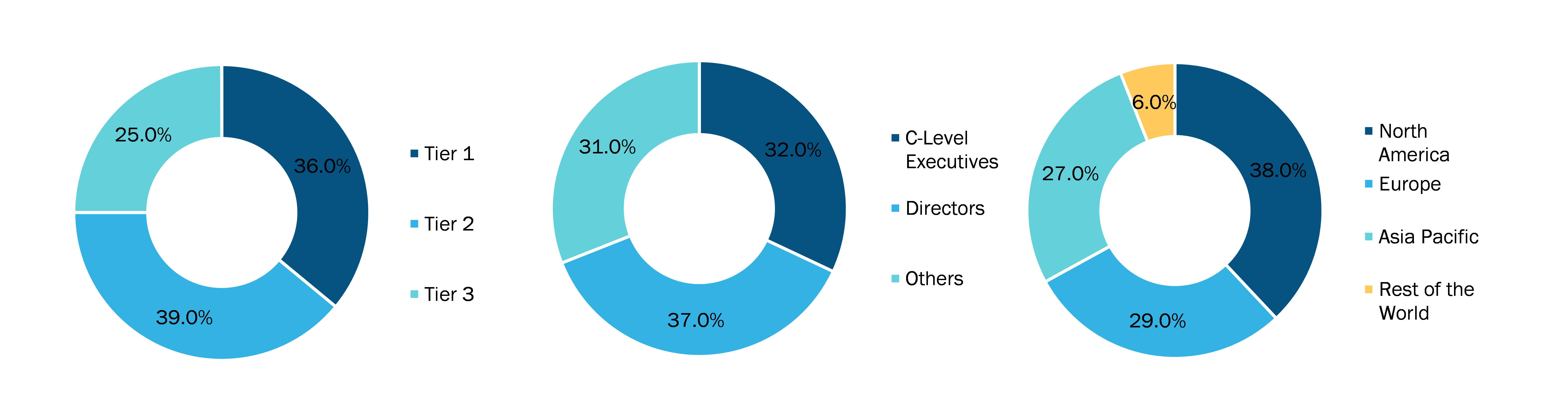
Below is the breakup of our primary respondents by company, designation, and region:
Once we receive the confirmation from primary research sources or primary respondents, we finalize the base year market estimation and forecast the data as per the macroeconomic and microeconomic factors assessed during data collection.
- Data Analysis:
Once data is validated through both secondary as well as primary respondents, we finalize the market estimations by hypothesis formulation and factor analysis at regional and country level.
- Macro-Economic Factor Analysis:
We analyse macroeconomic indicators such the gross domestic product (GDP), increase in the demand for goods and services across industries, technological advancement, regional economic growth, governmental policies, the influence of COVID-19, PEST analysis, and other aspects. This analysis aids in setting benchmarks for various nations/regions and approximating market splits. Additionally, the general trend of the aforementioned components aid in determining the market's development possibilities.
- Country Level Data:
Various factors that are especially aligned to the country are taken into account to determine the market size for a certain area and country, including the presence of vendors, such as headquarters and offices, the country's GDP, demand patterns, and industry growth. To comprehend the market dynamics for the nation, a number of growth variables, inhibitors, application areas, and current market trends are researched. The aforementioned elements aid in determining the country's overall market's growth potential.
- Company Profile:
The “Table of Contents” is formulated by listing and analyzing more than 25 - 30 companies operating in the market ecosystem across geographies. However, we profile only 10 companies as a standard practice in our syndicate reports. These 10 companies comprise leading, emerging, and regional players. Nonetheless, our analysis is not restricted to the 10 listed companies, we also analyze other companies present in the market to develop a holistic view and understand the prevailing trends. The “Company Profiles” section in the report covers key facts, business description, products & services, financial information, SWOT analysis, and key developments. The financial information presented is extracted from the annual reports and official documents of the publicly listed companies. Upon collecting the information for the sections of respective companies, we verify them via various primary sources and then compile the data in respective company profiles. The company level information helps us in deriving the base number as well as in forecasting the market size.
- Developing Base Number:
Aggregation of sales statistics (2020-2022) and macro-economic factor, and other secondary and primary research insights are utilized to arrive at base number and related market shares for 2022. The data gaps are identified in this step and relevant market data is analyzed, collected from paid primary interviews or databases. On finalizing the base year market size, forecasts are developed on the basis of macro-economic, industry and market growth factors and company level analysis.
- Data Triangulation and Final Review:
The market findings and base year market size calculations are validated from supply as well as demand side. Demand side validations are based on macro-economic factor analysis and benchmarks for respective regions and countries. In case of supply side validations, revenues of major companies are estimated (in case not available) based on industry benchmark, approximate number of employees, product portfolio, and primary interviews revenues are gathered. Further revenue from target product/service segment is assessed to avoid overshooting of market statistics. In case of heavy deviations between supply and demand side values, all thes steps are repeated to achieve synchronization.
We follow an iterative model, wherein we share our research findings with Subject Matter Experts (SME’s) and Key Opinion Leaders (KOLs) until consensus view of the market is not formulated – this model negates any drastic deviation in the opinions of experts. Only validated and universally acceptable research findings are quoted in our reports.
We have important check points that we use to validate our research findings – which we call – data triangulation, where we validate the information, we generate from secondary sources with primary interviews and then we re-validate with our internal data bases and Subject matter experts. This comprehensive model enables us to deliver high quality, reliable data in shortest possible time.
 Ottieni un campione gratuito per questo repot
Ottieni un campione gratuito per questo repot