Rapporto sull’analisi delle dimensioni del mercato e delle quote del mercato Analisi del testo | Previsioni 2031
Dati storici : 2021-2023 | Anno base : 2024 | Periodo di previsione : 2025-2031Dimensioni e previsioni del mercato dell'analisi del testo (2021-2031), quota globale e regionale, tendenze e opportunità di crescita. Copertura del rapporto di analisi: per tipo di distribuzione (basata su cloud e on-premise), tecnologia (NLP, AML e ibrida), applicazione (analisi predittiva, intelligence competitiva, rilevamento di frodi/spam e monitoraggio dei social media) e verticale (BFSI, telecomunicazioni, beni di largo consumo, governo, mondo accademico e istruzione, proprietà legale e intellettuale, sanità, prodotti farmaceutici, chimica e materiali, vendita al dettaglio e altri) e geografia (Nord America, Europa, Asia Pacifico e Sud e Centro America)
- Stato : Dati rilasciati
- Codice del report : TIPTE100000198
- Categoria : Tecnologia, media e telecomunicazioni
- Numero di pagine : 260
- Formati di report disponibili :




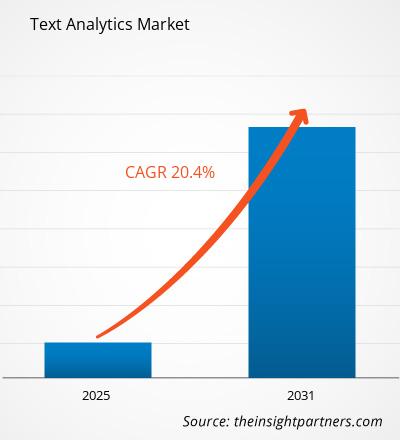
Si prevede che il mercato dell'analisi del testo raggiungerà i 29,53 miliardi di dollari entro il 2031. Si prevede che il mercato registrerà un CAGR del 18,1% nel periodo 2025-2031.
Il rapporto è suddiviso in base al tipo di implementazione (cloud e on-premise) e analizza ulteriormente il mercato in base alla tecnologia (NLP, AML, ibrida). Esamina inoltre il mercato per applicazione (analisi predittiva, intelligence competitiva, rilevamento frodi/spam, monitoraggio dei social media) e settore verticale (BFSI, telecomunicazioni, beni di largo consumo, pubblica amministrazione, università, istruzione, proprietà legale e intellettuale, sanità, prodotti farmaceutici, chimica e materiali, vendita al dettaglio). Per ciascuno di questi segmenti chiave viene fornita una ripartizione completa a livello globale, regionale e nazionale. Il rapporto include le dimensioni del mercato e le previsioni per tutti i segmenti, presentando i valori in dollari statunitensi. Fornisce inoltre statistiche chiave sullo stato attuale del mercato dei principali attori, insieme ad approfondimenti sulle tendenze prevalenti e sulle opportunità emergenti.
Scopo del rapporto
Il rapporto Text Analytics Market di The Insight Partners mira a descrivere il panorama attuale e la crescita futura, i principali fattori trainanti, le sfide e le opportunità. Ciò fornirà spunti a vari stakeholder aziendali, come:
- Fornitori/Produttori di tecnologia: per comprendere le dinamiche di mercato in evoluzione e conoscere le potenziali opportunità di crescita, consentendo loro di prendere decisioni strategiche informate.
- Investitori: per condurre un'analisi completa delle tendenze in merito al tasso di crescita del mercato, alle proiezioni finanziarie di mercato e alle opportunità esistenti lungo la catena del valore.
- Enti di regolamentazione: per regolamentare le politiche e le attività di controllo sul mercato con l'obiettivo di ridurre al minimo gli abusi, preservare la fiducia degli investitori e sostenere l'integrità e la stabilità del mercato.
Segmentazione del mercato dell'analisi del testo Tipo di distribuzione
- Basato su cloud e on-premise
Tecnologia
- NLP
- AML
- Ibrido
Applicazione
- Analisi predittiva
- Intelligence competitiva
- Rilevamento frodi/spam
- Monitoraggio dei social media
Verticale
- BFSI
- Telecomunicazioni
- Beni di largo consumo
- Pubblica amministrazione
- UniversitàIstruzione
- Legale e proprietà intellettuale
- Assistenza sanitaria
- Prodotti farmaceutici
- Chimica e materiali
- Vendita al dettaglio
Potrai personalizzare gratuitamente qualsiasi rapporto, comprese parti di questo rapporto, o analisi a livello di paese, pacchetto dati Excel, oltre a usufruire di grandi offerte e sconti per start-up e università
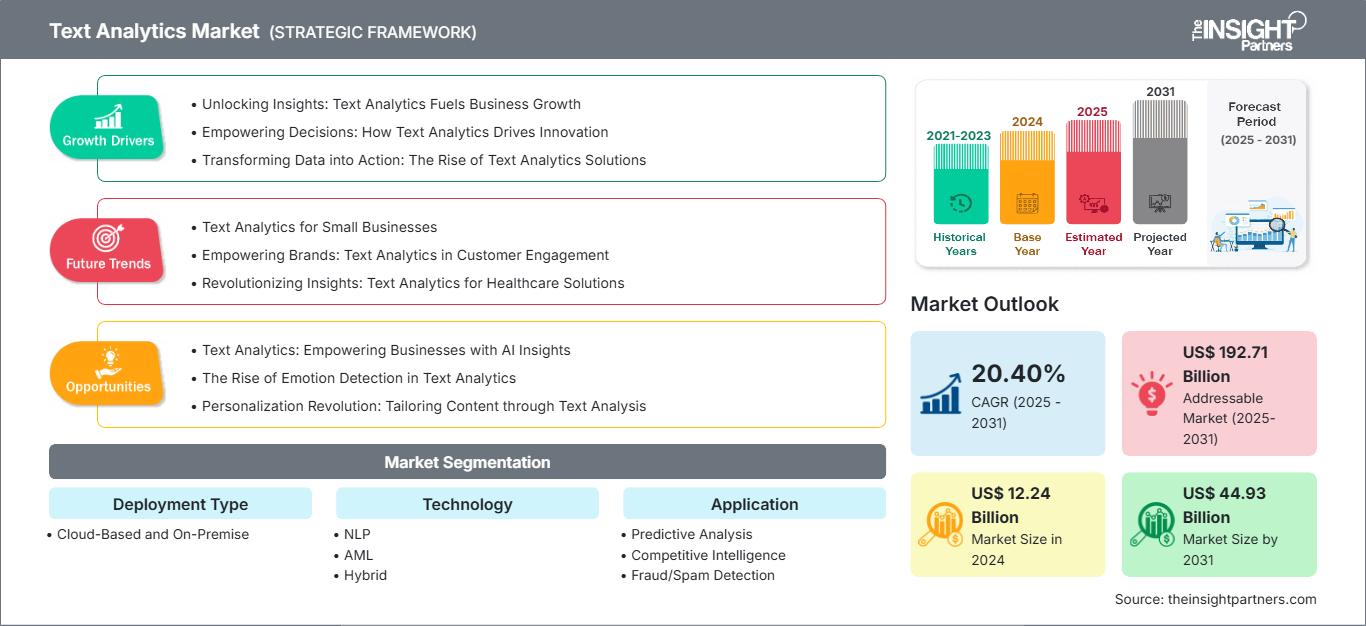
Mercato dell'analisi del testo: Approfondimenti strategici
-
Ottieni le principali tendenze chiave del mercato di questo rapporto.Questo campione GRATUITO includerà l'analisi dei dati, che vanno dalle tendenze di mercato alle stime e alle previsioni.
Fattori di crescita del mercato dell'analisi del testo
- Sbloccare le informazioni: l'analisi del testo alimenta la crescita aziendale
- Potenziare le decisioni: come l'analisi del testo guida l'innovazione
- Trasformare i dati in azione: l'ascesa delle soluzioni di analisi del testo
Tendenze future del mercato dell'analisi del testo
- Analisi del testo per le piccole imprese
- Potenziare i marchi: analisi del testo nel coinvolgimento dei clienti
- Rivoluzionare le informazioni: analisi del testo per le soluzioni sanitarie
Opportunità di mercato dell'analisi del testo
- Analisi del testo: potenziare le aziende con informazioni basate sull'intelligenza artificiale
- L'ascesa del rilevamento delle emozioni nell'analisi del testo
- Rivoluzione della personalizzazione: personalizzare i contenuti tramite l'analisi del testo
Mercato dell'analisi del testo
Le tendenze regionali e i fattori che influenzano il mercato dell'analisi del testo durante il periodo di previsione sono stati ampiamente spiegati dagli analisti di The Insight Partners. Questa sezione illustra anche i segmenti di mercato e la geografia della gestione delle malattie del ritmo cardiaco in Nord America, Europa, Asia-Pacifico, Medio Oriente e Africa, America meridionale e centrale.
Ambito del rapporto di mercato sull'analisi del testo
| Attributo del rapporto | Dettagli |
|---|---|
| Dimensioni del mercato in 2024 | US$ 9.22 Billion |
| Dimensioni del mercato per 2031 | US$ 29.53 Billion |
| CAGR globale (2025 - 2031) | 18.1% |
| Dati storici | 2021-2023 |
| Periodo di previsione | 2025-2031 |
| Segmenti coperti |
By Tipo di distribuzione
|
| Regioni e paesi coperti |
Nord America
|
| Leader di mercato e profili aziendali chiave |
|
Densità degli attori del mercato dell'analisi del testo: comprendere il suo impatto sulle dinamiche aziendali
Il mercato dell'analisi del testo è in rapida crescita, trainato dalla crescente domanda degli utenti finali, dovuta a fattori quali l'evoluzione delle preferenze dei consumatori, i progressi tecnologici e una maggiore consapevolezza dei vantaggi del prodotto. Con l'aumento della domanda, le aziende stanno ampliando la propria offerta, innovando per soddisfare le esigenze dei consumatori e sfruttando le tendenze emergenti, alimentando ulteriormente la crescita del mercato.
- Ottieni il Mercato dell'analisi del testo Panoramica dei principali attori chiave
Punti di forza
- Copertura completa: il rapporto analizza in modo esaustivo prodotti, servizi, tipologie e utenti finali del mercato dell'analisi del testo, offrendo una panoramica olistica.
- Analisi degli esperti: il rapporto è redatto sulla base della conoscenza approfondita di esperti e analisti del settore.
- Informazioni aggiornate: il rapporto garantisce la pertinenza aziendale grazie alla copertura di informazioni e tendenze dei dati recenti.
- Opzioni di personalizzazione: questo rapporto può essere personalizzato per soddisfare le esigenze specifiche del cliente e adattarsi in modo appropriato alle strategie aziendali.
Il rapporto di ricerca sul mercato dell'analisi del testo può quindi contribuire a guidare il percorso di decodificazione e comprensione dello scenario del settore e delle prospettive di crescita. Sebbene possano esserci alcune valide preoccupazioni, i vantaggi complessivi di questo rapporto tendono a superare gli svantaggi.

Ankita è una dinamica professionista della ricerca di mercato e della consulenza con oltre 8 anni di esperienza nei settori della tecnologia, dei media, dell'ICT, dell'elettronica e dei semiconduttori. Ha guidato e portato a termine con successo oltre 100 incarichi di consulenza e ricerca per clienti globali come Microsoft, Oracle, NEC Corporation, SAP, KPMG ed Expeditors International. Le sue competenze principali includono la valutazione del mercato, l'analisi dei dati, le previsioni, la formulazione di strategie, l'intelligence competitiva e la redazione di report.
Ankita è esperta nella gestione di cicli di progetto completi, dalla progettazione di proposte pre-vendita e discussioni con i clienti fino alla fornitura di insight fruibili post-vendita. È esperta nella gestione di team interfunzionali, nella strutturazione di moduli di ricerca complessi e nell'allineamento delle soluzioni agli obiettivi aziendali specifici del cliente. Le sue eccellenti capacità di comunicazione, leadership e presentazione le hanno permesso di fornire costantemente risultati orientati al valore in contesti di mercato in rapida evoluzione.
- Analisi storica (2 anni), anno base, previsione (7 anni) con CAGR
- Analisi PEST e SWOT
- Valore/volume delle dimensioni del mercato - Globale, Regionale, Nazionale
- Industria e panorama competitivo
- Set di dati Excel
Testimonianze
Il report di mercato sui sistemi SCADA di Insight Partners è completo, con preziosi spunti sulle tendenze attuali e sulle previsioni future. Il team si è dimostrato altamente professionale, reattivo e disponibile in ogni fase del progetto. Siamo molto soddisfatti e consigliamo vivamente i loro servizi.
RAN KEDEM Partner, Reali Technologies LTDsHo richiesto un report su un mercato software molto specifico e il team lo ha prodotto in pochi giorni. Le informazioni erano molto pertinenti e ben presentate. Ho quindi richiesto alcune modifiche e aggiunte al report. Il team è stato ancora una volta molto reattivo e ho ricevuto il report finale in meno di una settimana.
JEAN-HERVE JENN Presidente, Future AnalyticaAbbiamo collaborato con The Insight Partners per un importante studio di mercato e una previsione. Ci hanno fornito informazioni chiare su opportunità e rischi, che ci hanno aiutato a definire i nostri piani. La loro ricerca è stata facile da usare e basata su dati solidi. Ci ha aiutato a prendere decisioni intelligenti e consapevoli. Li consigliamo vivamente.
PIYUSH NAGPAL Vicepresidente senior, Abbaglianti globaliInsight Partners ha fornito ricerche di mercato approfondite e ben strutturate, con una solida competenza nel settore. Il loro team si è dimostrato professionale e reattivo in ogni fase. Il sito web intuitivo ha reso l'accesso ai report di settore semplice e immediato. Li consigliamo vivamente per servizi di ricerca affidabili e di alta qualità.
YUKIHIKO ADACHI Amministratore delegato, Deep Blue, LLC.Questa è la prima volta che acquisto un report di mercato da The Insight Partners. Sebbene inizialmente fossi indeciso, ho visitato il loro sito web e mi sono sentito più a mio agio nell'acquistare un report di mercato. Sono completamente soddisfatto della qualità del report e del servizio clienti. Avevo diverse domande e commenti sul report iniziale, ma dopo un paio di conversazioni via email con il loro analista credo di avere un report che posso utilizzare come input per il nostro processo di pianificazione strategica. Grazie mille per aver dedicato del tempo extra e aver reso questa esperienza positiva. Consiglierò sicuramente il vostro servizio ad altri e sarete la mia prima persona a cui rivolgermi quando avremo bisogno di ulteriori dati di mercato.
GIOVANNI SUZUKI Presidente e Amministratore Delegato, Consigliere di Amministrazione, Tecnologie BKDesidero esprimere la mia gratitudine per il supporto e la professionalità dimostrati nel rispondere alla mia richiesta di informazioni sul mercato dei dispositivi medici in vitro per malattie infettive in Nigeria. Apprezzo la vostra pazienza, la vostra guida e la vostra disponibilità a offrirmi uno sconto, che alla fine ci ha permesso di concludere l'affare. Non vedo l'ora di collaborare con The Insight Partners in futuro, grazie anche all'impressione che mi avete lasciato dopo questo primo incontro.
Dott. Chijioke AMMINISTRATORE DELEGATO DI ONYIA, PineCrest Healthcare Ltd.Motivo dell'acquisto
- Processo decisionale informato
- Comprensione delle dinamiche di mercato
- Analisi competitiva
- Analisi dei clienti
- Previsioni di mercato
- Mitigazione del rischio
- Pianificazione strategica
- Giustificazione degli investimenti
- Identificazione dei mercati emergenti
- Miglioramento delle strategie di marketing
- Aumento dell'efficienza operativa
- Allineamento alle tendenze normative










Sblocca sconti esclusivi sui report
Richiedi ora



 Ottieni un campione gratuito per - Mercato dell'analisi del testo
Ottieni un campione gratuito per - Mercato dell'analisi del testo