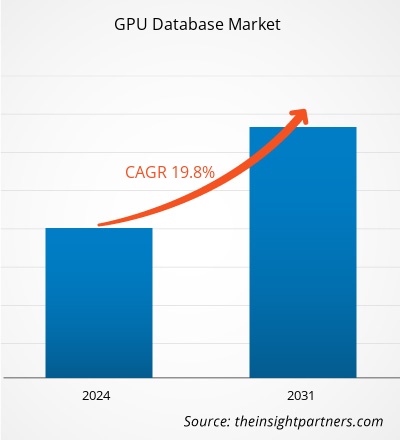
GPU データベース市場規模は、2023 年の 4 億 6,237 万ドルから 2031 年には 1 億 9,5623 万ドルに達すると予測されています。市場は 2023 年から 2031 年にかけて 19.8% の CAGR を記録すると予想されています。データの増加とデータ駆動型産業の成長は、今後も市場の主要なトレンドであり続けると思われます。
GPU データベース市場分析
データ駆動型産業の成長は、GPU データベース市場の主要な推進要因の 1 つです。デジタル化の進展と、大規模なデータセットを処理するソリューションを求める企業の傾向が、市場の成長を後押ししています。GPU データベースは、人工知能、機械学習、ディープラーニング、モノのインターネット (IoT)、地理空間分析などの新興技術に応用されており、GPU データベース市場の成長に大きなチャンスを生み出しています。
GPU データベース市場の概要
GPU データベースは、グラフィック プロセッシング ユニット (GPU) を使用してデータベース操作を実行します。GPU は、高解像度の画像やビデオをすばやくレンダリングするように設計されたプログラム可能なプロセッサです。GPU データベースは、CPU と並列で動作するため、大量のデータを CPU よりも迅速かつ効率的に処理します。そのため、GPU データベースは一般的に高速で、分析に適しています。分析は、さまざまな種類のデータや大量のデータをより柔軟に処理できます。
要件に合わせてレポートをカスタマイズする
このレポートの一部、国レベルの分析、Excelデータパックなど、あらゆるレポートを無料でカスタマイズできます。また、スタートアップや大学向けのお得なオファーや割引もご利用いただけます。
GPU データベース市場:

- このレポートの主要な市場動向を入手してください。この無料サンプルには、市場動向から見積もりや予測に至るまでのデータ分析が含まれます。
GPU データベース市場の推進要因と機会
データの増加は市場に有利に働く
デジタル化の到来により、データは驚異的な速度で生成されています。データ分析技術の助けを借りて、隠れたパターンや洞察を引き出すには、さまざまな種類、量、速度のデータを分析および処理する必要があります。従来の分析では、最適な分析技術やテクノロジーを提供できません。このため、GPU データベースが必要になります。超並列処理機能を備えた GPU データベースは、コスト効率の高い高性能コンピューティングを提供します。GPU データベースは、大規模なデータセットを処理するための理想的なソリューションであり、このテクノロジーの需要を促進しています。
データ駆動型産業からの需要。
GPU データは高い計算能力を持っています。並列処理機能により、図に示すように、CPU のみを含む構成よりも最大 100 倍高速にデータを処理できます。そのため、BFSI、メディア & エンターテインメントなどのさまざまなデータ駆動型業界では、データ分析アプリケーションの処理集約型ワークロードに対するソリューションが求められており、これが GPU データベースの需要を促進しています。市場プレーヤーは、この需要に応えるソリューションを立ち上げています。Graphistry は、GPU アクセラレーションによる視覚的なグラフ分析を顧客に提供するために、Hub Pro (Graphistry Hub for Professionals) をリリースしました。Graphistry Hub Pro は、個人向けのセキュリティ、価格設定、メンテナンス、およびチーム向けの今後の Hub Organizations を解決します。(出典: Graphistry、プレスリリース、2021 年 9 月)
GPU データベース市場レポートのセグメンテーション分析
GPU データベース市場分析の導出に貢献した主要なセグメントは、コンポーネント、展開、アプリケーション、および業界垂直です。
- コンポーネントに基づいて、GPUデータベース市場はツールとサービスに分かれています。ツールセグメントは2023年に市場で最大のシェアを占めました。
- 展開別に見ると、市場はクラウドベースとオンプレミスに分かれています。クラウドベースは最も高い CAGR で成長すると予想されています。
- アプリケーション別に見ると、市場は不正検出と防止、ガバナンス・リスクとコンプライアンス (GRC)、顧客体験管理、予測保守、サプライチェーン管理、脅威インテリジェンス、その他に分類されています。顧客体験管理は 2023 年に市場で大きなシェアを占めました。
- 業界別に見ると、市場はBFSI、ITおよび通信、小売および電子商取引、ヘルスケア、輸送および物流、政府および防衛、その他に分類されています。2023年にはBFSIが市場で大きなシェアを占めました。
地域別 GPU データベース市場シェア分析
GPU データベース市場レポートの地理的範囲は、主に北米、アジア太平洋、ヨーロッパ、中東およびアフリカ、南米および中米の 5 つの地域に分かれています。
アジア太平洋地域は、最も高い CAGR で成長すると予想されています。インドや中国などの発展途上国におけるデジタル化の進展と高度なデータ分析技術に対する需要の高まりが、この地域の市場成長を牽引しています。BFSI、ヘルスケア、製造などのデータ駆動型産業におけるデジタル変革が、市場の成長をさらに牽引しています。大規模なデータセットから洞察を抽出する需要の高まりが、アジア太平洋地域の市場成長を牽引しています。
GPU データベース市場の地域別分析
予測期間を通じて GPU データベース市場に影響を与える地域的な傾向と要因は、Insight Partners のアナリストによって徹底的に説明されています。このセクションでは、北米、ヨーロッパ、アジア太平洋、中東およびアフリカ、南米および中米にわたる GPU データベース市場のセグメントと地理についても説明します。
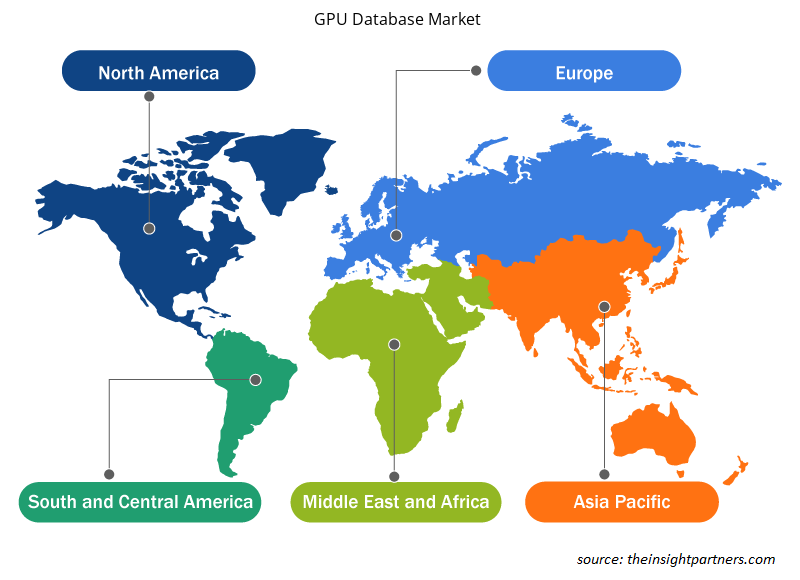
- GPUデータベース市場の地域別データを入手
GPUデータベース市場レポートの範囲
| レポート属性 | 詳細 |
|---|---|
| 2023年の市場規模 | 4億6,237万米ドル |
| 2031年までの市場規模 | 19億5,623万米ドル |
| 世界のCAGR(2023年~2031年) | 19.8% |
| 履歴データ | 2021-2022 |
| 予測期間 | 2024-2031 |
| 対象セグメント | コンポーネント別
|
| 対象地域と国 | 北米
|
| 市場リーダーと主要企業プロフィール |
|
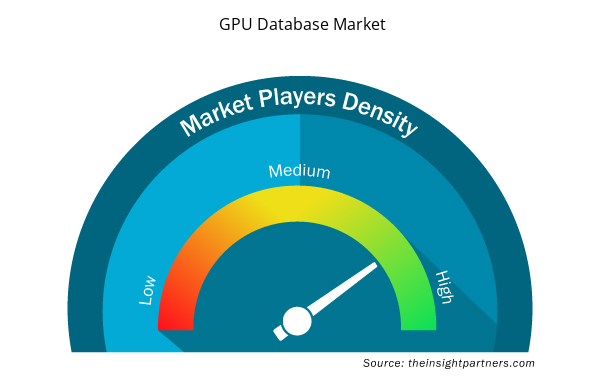
GPU データベース市場のプレーヤー密度: ビジネスダイナミクスへの影響を理解する
GPU データベース市場は、消費者の嗜好の変化、技術の進歩、製品の利点に対する認識の高まりなどの要因により、エンドユーザーの需要が高まり、急速に成長しています。需要が高まるにつれて、企業は提供を拡大し、消費者のニーズを満たすために革新し、新たなトレンドを活用し、市場の成長をさらに促進しています。
市場プレーヤー密度とは、特定の市場または業界内で活動している企業または会社の分布を指します。これは、特定の市場スペースに、その市場規模または総市場価値に対してどれだけの競合相手 (市場プレーヤー) が存在するかを示します。
GPU データベース市場で事業を展開している主要企業は次のとおりです。
- ブリット
- グラフィック
- H2O.ai
- ジェドックス
- キネティカDB株式会社
- 株式会社ネオ4ジェイ
免責事項:上記の企業は、特定の順序でランク付けされていません。
- GPUデータベース市場のトップキープレーヤーの概要を入手
GPU データベース市場のニュースと最近の動向
GPU データベース市場は、重要な企業出版物、協会データ、データベースなど、一次調査と二次調査後の定性的および定量的データを収集することによって評価されます。GPU データベース市場の動向のいくつかを以下に示します。
- NVIDIA と HP Inc. は、生成 AI 開発の基盤となるデータの準備と処理作業を高速化するために、NVIDIA CUDA-X データ処理ライブラリを HP AI ワークステーション ソリューションに統合すると発表しました。NVIDIA CUDA コンピューティング プラットフォーム上に構築された CUDA-X ライブラリは、テーブル、テキスト、画像、ビデオなど、さまざまなデータ タイプのデータ処理を高速化します。これには、コードを変更することなく、CPU のみのシステムではなく NVIDIA RTX 6000 Ada 世代 GPU を使用して、pandas ソフトウェアを使用する約 1,000 万人のデータ サイエンティストの作業を最大 110 倍高速化する NVIDIA RAPIDS cuDF ライブラリが含まれます。(出典: NVIDIA、プレス リリース、2024 年 3 月)
- ベクターデータベース技術の先駆者である Zilliz は、RAPIDS cuVS ライブラリの一部である NVIDIA の CUDA-Accelerated Graph Index for Vector Retrieval (CAGRA) を搭載した画期的な GPU インデックス機能により、ベクター検索機能の新しい標準を確立する Milvus 2.4 のリリースを発表しました。(出典: Zilliz、プレスリリース、2024 年 3 月)
GPU データベース市場レポートの対象範囲と成果物
「GPU データベース市場の規模と予測 (2021 ~ 2031 年)」レポートでは、以下の分野をカバーする市場の詳細な分析を提供しています。
- 対象範囲に含まれるすべての主要市場セグメントについて、世界、地域、国レベルでのGPUデータベース市場規模と予測
- GPUデータベース市場の動向と、推進要因、制約、主要な機会などの市場動向
- 詳細なPEST/ポーターの5つの力とSWOT分析
- 主要な市場動向、世界および地域の枠組み、主要プレーヤー、規制、最近の市場動向を網羅した GPU データベース市場分析
- 市場集中、ヒートマップ分析、主要プレーヤー、GPUデータベース市場の最近の動向を網羅した業界展望と競争分析
- 詳細な企業プロフィール
- 過去2年間の分析、基準年、CAGRによる予測(7年間)
- PEST分析とSWOT分析
- 市場規模価値/数量 - 世界、地域、国
- 業界と競争環境
- Excel データセット

Report Coverage
Revenue forecast, Company Analysis, Industry landscape, Growth factors, and Trends
Segment Covered
This text is related
to segments covered.

Regional Scope
North America, Europe, Asia Pacific, Middle East & Africa, South & Central America
Country Scope
This text is related
to country scope.
よくある質問
The estimated value of the GPU database market will be US$ 1956.23 million by 2031.
BRYTLYT; GRAPHISTRY; H2O.ai; Jedox; Kinetica DB Inc.; Neo4J, INC.; SQREAM DB; ZILLIZ ; HEAVY.AI; and NVIDIA CORPORATION are some of the key players operating in the GPU database market.
Massive data generation from end-users such as BFSI and media & entertainment is considered a key trend in the GPU database market.
The rise in data and the growing data-driven industries are the key driving factors impacting the GPU database market.
The global GPU database market is estimated to register a CAGR of 19.8% during the forecast period 2023–2031.
Trends and growth analysis reports related to Technology, Media and Telecommunications : READ MORE..
The Insight Partners performs research in 4 major stages: Data Collection & Secondary Research, Primary Research, Data Analysis and Data Triangulation & Final Review.
- Data Collection and Secondary Research:
As a market research and consulting firm operating from a decade, we have published and advised several client across the globe. First step for any study will start with an assessment of currently available data and insights from existing reports. Further, historical and current market information is collected from Investor Presentations, Annual Reports, SEC Filings, etc., and other information related to company’s performance and market positioning are gathered from Paid Databases (Factiva, Hoovers, and Reuters) and various other publications available in public domain.
Several associations trade associates, technical forums, institutes, societies and organization are accessed to gain technical as well as market related insights through their publications such as research papers, blogs and press releases related to the studies are referred to get cues about the market. Further, white papers, journals, magazines, and other news articles published in last 3 years are scrutinized and analyzed to understand the current market trends.
- Primary Research:
The primarily interview analysis comprise of data obtained from industry participants interview and answers to survey questions gathered by in-house primary team.
For primary research, interviews are conducted with industry experts/CEOs/Marketing Managers/VPs/Subject Matter Experts from both demand and supply side to get a 360-degree view of the market. The primary team conducts several interviews based on the complexity of the markets to understand the various market trends and dynamics which makes research more credible and precise.
A typical research interview fulfils the following functions:
- Provides first-hand information on the market size, market trends, growth trends, competitive landscape, and outlook
- Validates and strengthens in-house secondary research findings
- Develops the analysis team’s expertise and market understanding
Primary research involves email interactions and telephone interviews for each market, category, segment, and sub-segment across geographies. The participants who typically take part in such a process include, but are not limited to:
- Industry participants: VPs, business development managers, market intelligence managers and national sales managers
- Outside experts: Valuation experts, research analysts and key opinion leaders specializing in the electronics and semiconductor industry.
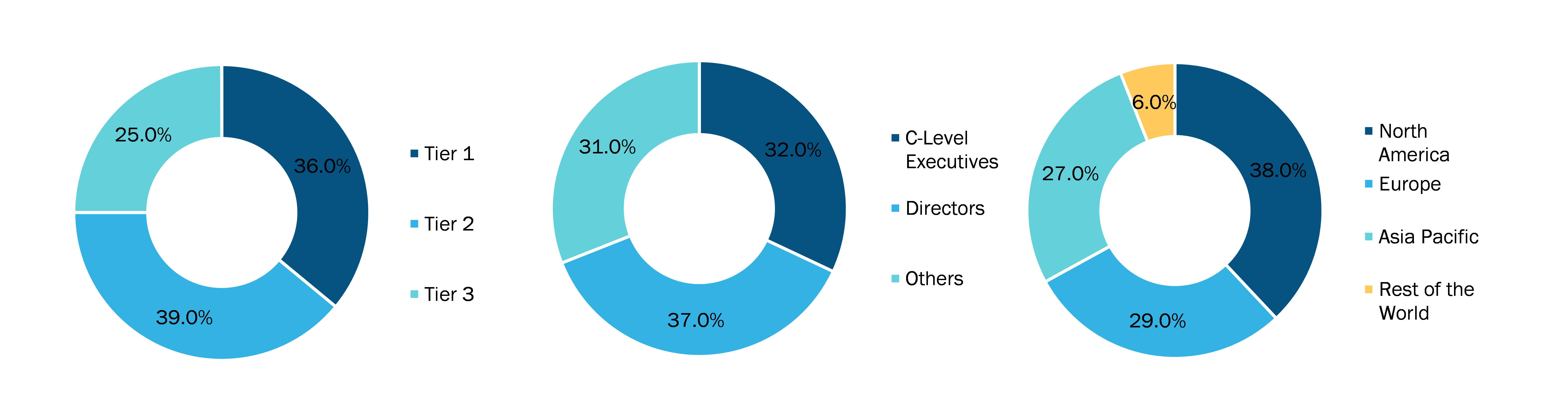
Below is the breakup of our primary respondents by company, designation, and region:
Once we receive the confirmation from primary research sources or primary respondents, we finalize the base year market estimation and forecast the data as per the macroeconomic and microeconomic factors assessed during data collection.
- Data Analysis:
Once data is validated through both secondary as well as primary respondents, we finalize the market estimations by hypothesis formulation and factor analysis at regional and country level.
- Macro-Economic Factor Analysis:
We analyse macroeconomic indicators such the gross domestic product (GDP), increase in the demand for goods and services across industries, technological advancement, regional economic growth, governmental policies, the influence of COVID-19, PEST analysis, and other aspects. This analysis aids in setting benchmarks for various nations/regions and approximating market splits. Additionally, the general trend of the aforementioned components aid in determining the market's development possibilities.
- Country Level Data:
Various factors that are especially aligned to the country are taken into account to determine the market size for a certain area and country, including the presence of vendors, such as headquarters and offices, the country's GDP, demand patterns, and industry growth. To comprehend the market dynamics for the nation, a number of growth variables, inhibitors, application areas, and current market trends are researched. The aforementioned elements aid in determining the country's overall market's growth potential.
- Company Profile:
The “Table of Contents” is formulated by listing and analyzing more than 25 - 30 companies operating in the market ecosystem across geographies. However, we profile only 10 companies as a standard practice in our syndicate reports. These 10 companies comprise leading, emerging, and regional players. Nonetheless, our analysis is not restricted to the 10 listed companies, we also analyze other companies present in the market to develop a holistic view and understand the prevailing trends. The “Company Profiles” section in the report covers key facts, business description, products & services, financial information, SWOT analysis, and key developments. The financial information presented is extracted from the annual reports and official documents of the publicly listed companies. Upon collecting the information for the sections of respective companies, we verify them via various primary sources and then compile the data in respective company profiles. The company level information helps us in deriving the base number as well as in forecasting the market size.
- Developing Base Number:
Aggregation of sales statistics (2020-2022) and macro-economic factor, and other secondary and primary research insights are utilized to arrive at base number and related market shares for 2022. The data gaps are identified in this step and relevant market data is analyzed, collected from paid primary interviews or databases. On finalizing the base year market size, forecasts are developed on the basis of macro-economic, industry and market growth factors and company level analysis.
- Data Triangulation and Final Review:
The market findings and base year market size calculations are validated from supply as well as demand side. Demand side validations are based on macro-economic factor analysis and benchmarks for respective regions and countries. In case of supply side validations, revenues of major companies are estimated (in case not available) based on industry benchmark, approximate number of employees, product portfolio, and primary interviews revenues are gathered. Further revenue from target product/service segment is assessed to avoid overshooting of market statistics. In case of heavy deviations between supply and demand side values, all thes steps are repeated to achieve synchronization.
We follow an iterative model, wherein we share our research findings with Subject Matter Experts (SME’s) and Key Opinion Leaders (KOLs) until consensus view of the market is not formulated – this model negates any drastic deviation in the opinions of experts. Only validated and universally acceptable research findings are quoted in our reports.
We have important check points that we use to validate our research findings – which we call – data triangulation, where we validate the information, we generate from secondary sources with primary interviews and then we re-validate with our internal data bases and Subject matter experts. This comprehensive model enables us to deliver high quality, reliable data in shortest possible time.
 このレポートの無料サンプルを入手する
このレポートの無料サンプルを入手する