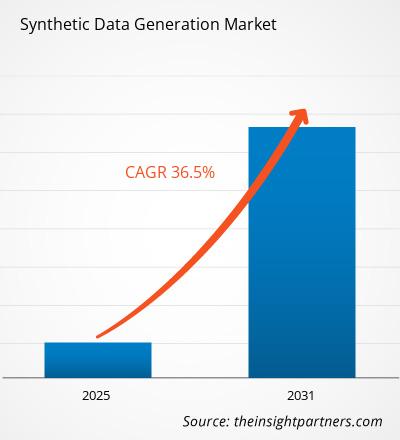
합성 데이터 생성 시장은 2025년부터 2031년까지 36.5%의 CAGR을 기록할 것으로 예상되며, 시장 규모는 2024년의 XX백만 달러에서 2031년의 XX백만 달러로 확대될 것입니다.
본 보고서는 솔루션/플랫폼 및 서비스 제공, 데이터 유형(표 형식, 텍스트, 이미지, 비디오), 애플리케이션(AI/ML 교육 및 개발, 테스트 데이터 관리)별로 세분화되어 있습니다. 글로벌 분석은 지역 및 주요 국가별로 더욱 세분화되어 있습니다. 본 보고서는 위 분석 및 세그먼트에 대한 가치를 미국 달러(USD)로 제공합니다.
보고서의 목적
The Insight Partners의 합성 데이터 생성 시장 보고서는 현재 상황과 미래 성장, 주요 추진 요인, 과제, 그리고 기회를 설명합니다. 이를 통해 다음과 같은 다양한 비즈니스 이해관계자에게 통찰력을 제공할 수 있습니다.
- 기술 공급업체/제조업체: 변화하는 시장 역학을 이해하고 잠재적인 성장 기회를 파악하여 정보에 입각한 전략적 결정을 내릴 수 있도록 합니다.
- 투자자: 시장 성장률, 시장 재무 전망, 가치 사슬 전반에 존재하는 기회에 대한 포괄적인 추세 분석을 수행합니다.
- 규제 기관: 시장의 정책과 경찰 활동을 규제하여 남용을 최소화하고, 투자자의 신뢰와 확신을 유지하며, 시장의 성실성과 안정성을 옹호합니다.
합성 데이터 생성 시장 세분화
헌금
- 솔루션/플랫폼 및 서비스
데이터 유형
- 표의
- 텍스트
- 영상
- 동영상
애플리케이션
- AI/ML 교육 및 개발
- 테스트 데이터 관리
지리학
- 북아메리카
- 유럽
- 아시아 태평양
- 중동 및 아프리카
- 남미와 중미
귀하의 요구 사항에 맞게 이 보고서를 사용자 정의하세요
이 보고서의 일부 또는 국가 수준 분석, Excel 데이터 팩을 포함하여 모든 보고서에 대한 사용자 정의를 무료로 받을 수 있으며, 신생 기업 및 대학을 위한 훌륭한 혜택과 할인도 이용할 수 있습니다.
합성 데이터 생성 시장: 전략적 통찰력

- 이 보고서에서 주요 시장 동향을 알아보세요.이 무료 샘플에는 시장 동향부터 추정치 및 예측까지 다양한 데이터 분석이 포함됩니다.
합성 데이터 생성 시장 성장 동인
- 데이터 프라이버시에 대한 수요 증가: 합성 데이터를 통해 기업은 사용자 프라이버시를 침해하지 않고 데이터 세트를 생성할 수 있습니다. 특히 의료 및 금융과 같이 민감한 개인 정보가 관련된 분야에서 개인정보 보호 문제를 완화하는 효과적인 솔루션을 제공합니다. 실제 데이터를 모방하는 인공 데이터를 생성함으로써 기업은 실제 신원을 노출하지 않고 AI 모델을 학습시킬 수 있으며, GDPR과 같은 데이터 보호 규정을 준수하는 데 도움이 됩니다.
- AI 및 머신러닝의 발전: AI 및 머신러닝 기술의 발전은 합성 데이터에 대한 수요를 증가시켰습니다. 복잡한 모델을 학습하기 위해 방대하고 다양한 데이터 세트가 필요함에 따라, 합성 데이터 생성은 특히 틈새 시장이나 매우 특수한 애플리케이션의 데이터 부족 문제를 해결하는 데 도움이 됩니다. 합성 데이터는 값비싸거나 접근하기 어려운 실제 데이터 없이도 고품질의 다양한 데이터를 제공함으로써 모델 개발을 가속화합니다.
- 비용 효율적인 데이터 생성: 실제 데이터를 수집하고 레이블을 지정하는 작업은 특히 자율주행이나 의료 연구와 같은 작업의 경우 비용과 시간이 많이 소요될 수 있습니다. 합성 데이터 생성은 이러한 비용을 크게 절감합니다. 기업은 방대한 양의 데이터를 빠르고 저렴하게 생성하여 모델 학습 및 테스트를 더욱 빠르게 진행할 수 있습니다. 특히 지속적인 업데이트나 대규모 시뮬레이션이 필요한 분야에서 유용합니다.
합성 데이터 생성 시장 미래 동향
- AI 및 딥러닝과의 통합: 합성 데이터를 고급 AI 및 딥러닝 모델과 통합하는 추세가 증가하고 있습니다. AI 기반 합성 데이터 생성 도구는 더욱 정교해지면서 특정 학습 요구에 맞춘 고품질의 사실적인 데이터 세트를 생성할 수 있습니다. 딥러닝 기술이 방대한 양의 레이블링된 데이터를 요구함에 따라, 합성 데이터를 활용하여 모델을 더욱 효율적으로 학습하는 방식이 여러 산업 분야에서 주목을 받고 있습니다.
- 의료 분야에서 합성 데이터 도입 증가: 데이터 개인정보 보호에 대한 우려와 규제 요건이 강화됨에 따라, 의료 분야에서는 머신러닝 모델 학습을 위해 합성 데이터를 점점 더 많이 도입하고 있습니다. 의료 기관들은 합성 데이터 세트를 활용하여 환자 익명성을 보장하면서 의료 영상, 신약 개발, 환자 관리 모델 솔루션을 개발하고 있습니다. 이러한 추세는 개인정보를 침해하지 않으면서 AI 정확도를 향상시킬 수 있는 대규모 데이터 세트에 대한 필요성에서 비롯됩니다.
- 협업 및 전략적 파트너십: 합성 데이터 시장의 많은 기업들이 서비스 강화를 위해 전략적 제휴를 맺고 있습니다. AI 기업, 연구 기관 또는 의료 서비스 제공업체와 협력함으로써, 이러한 기업들은 서로의 전문성과 자원을 활용하여 합성 데이터 생성 기술을 발전시키고자 합니다. 이러한 파트너십은 다양한 산업에 맞춰 더욱 맞춤화된 솔루션 개발에 기여하여 합성 데이터 도입을 가속화하고 있습니다.
합성 데이터 생성 시장 기회
- 자율주행차 개발: 자율주행차 산업은 현실 세계에서 재현하기 어렵거나 위험할 수 있는 다양한 주행 시나리오를 시뮬레이션하기 위해 합성 데이터를 활용할 수 있습니다. 합성 데이터를 통해 다양한 도로 상황, 기상 상황, 교통 상황을 생성할 수 있으며, 이는 자율주행차에서 AI 시스템을 훈련하고 테스트하는 데 필수적입니다. 이러한 기회는 안전성과 신뢰성을 보장하는 동시에 개발 프로세스를 가속화하는 데 도움이 됩니다.
- AI 및 머신러닝 연구: AI 및 머신러닝 연구자들은 실제 데이터가 부족하거나 대표성이 부족한 경우 합성 데이터를 활용하여 알고리즘을 학습할 수 있습니다. 자연어 처리(NLP)나 컴퓨터 비전과 같은 분야에서 합성 데이터는 학습 목적에 맞는 특정 데이터 세트를 생성할 수 있는 유연성을 제공하여 독점 데이터에 대한 의존도를 줄이고 학계 및 산업 연구의 새로운 지평을 열어줍니다.
- 금융 부문 및 사기 탐지: 금융 업계에서는 합성 데이터를 활용하여 민감한 고객 정보를 노출하지 않고도 거래, 금융 이벤트 또는 사기 행위를 시뮬레이션할 수 있습니다. 금융 기관은 합성 데이터셋을 기반으로 AI 모델을 학습시킴으로써 사기 탐지 역량을 향상시키고 데이터 프라이버시를 보장하는 동시에 위험을 완화할 수 있습니다. 또한, 이를 통해 더욱 다양한 데이터셋을 생성하여 더 나은 재무 예측 및 시장 동향 분석을 수행할 수 있습니다.
합성 데이터 생성 시장 지역별 통찰력
Insight Partners의 분석가들은 예측 기간 동안 합성 데이터 생성 시장에 영향을 미치는 지역별 동향과 요인을 면밀히 분석했습니다. 이 섹션에서는 북미, 유럽, 아시아 태평양, 중동 및 아프리카, 중남미 지역의 합성 데이터 생성 시장 부문 및 지역별 현황도 살펴봅니다.
- 합성 데이터 생성 시장을 위한 지역별 데이터 확보
합성 데이터 생성 시장 보고서 범위
| 보고서 속성 | 세부 |
|---|---|
| 2024년 시장 규모 | 미화 XX백만 달러 |
| 2031년까지 시장 규모 | 미화 XX백만 달러 |
| 글로벌 CAGR(2025~2031년) | 36.5% |
| 역사적 데이터 | 2021-2023 |
| 예측 기간 | 2025-2031 |
| 다루는 세그먼트 | 제공함으로써
|
| 포함된 지역 및 국가 | 북아메리카
|
| 시장 선도 기업 및 주요 회사 프로필 |
|
합성 데이터 생성 시장 참여자 밀도: 비즈니스 역학에 미치는 영향 이해
합성 데이터 생성 시장은 소비자 선호도 변화, 기술 발전, 그리고 제품 이점에 대한 인식 제고 등의 요인으로 인한 최종 사용자 수요 증가에 힘입어 빠르게 성장하고 있습니다. 수요가 증가함에 따라 기업들은 제품 및 서비스를 확장하고, 소비자 니즈를 충족하기 위한 혁신을 추진하며, 새로운 트렌드를 적극 활용하고 있으며, 이는 시장 성장을 더욱 가속화하고 있습니다.
시장 참여자 밀도는 특정 시장이나 산업 내에서 활동하는 기업들의 분포를 나타냅니다. 이는 특정 시장 공간에 얼마나 많은 경쟁자(시장 참여자)가 존재하는지를 규모나 전체 시장 가치 대비로 나타냅니다.
합성 데이터 생성 시장에서 운영되는 주요 회사는 다음과 같습니다.
- 마이크로소프트
- IBM
- AWS
- 엔비디아
- 오픈AI
면책 조항 : 위에 나열된 회사는 특정 순서에 따라 순위가 매겨지지 않았습니다.
- 합성 데이터 생성 시장의 주요 주요 업체 개요를 확인하세요.
주요 판매 포인트
- 포괄적인 범위: 이 보고서는 합성 데이터 생성 시장의 제품, 서비스, 유형 및 최종 사용자에 대한 분석을 포괄적으로 다루어 전체적인 상황을 제공합니다.
- 전문가 분석: 이 보고서는 업계 전문가와 분석가의 심층적인 이해를 바탕으로 작성되었습니다.
- 최신 정보: 이 보고서는 최신 정보와 데이터 동향을 다루므로 비즈니스 관련성이 보장됩니다.
- 사용자 정의 옵션: 이 보고서는 특정 클라이언트 요구 사항에 맞게 사용자 정의하여 비즈니스 전략에 적합하게 만들 수 있습니다.
따라서 합성 데이터 생성 시장 연구 보고서는 업계 상황과 성장 전망을 해석하고 이해하는 데 앞장서는 데 도움이 될 수 있습니다. 몇 가지 우려 사항이 있을 수 있지만, 이 보고서의 전반적인 장점은 단점보다 훨씬 큰 것으로 보입니다.
- 역사적 분석(2년), 기준 연도, CAGR을 포함한 예측(7년)
- PEST 및 SWOT 분석
- 시장 규모 가치/양 - 글로벌, 지역, 국가
- 산업 및 경쟁 환경
- Excel 데이터 세트

Report Coverage
Revenue forecast, Company Analysis, Industry landscape, Growth factors, and Trends
Segment Covered
This text is related
to segments covered.

Regional Scope
North America, Europe, Asia Pacific, Middle East & Africa, South & Central America
Country Scope
This text is related
to country scope.
자주 묻는 질문
Some of the customization options available based on the request are an additional 3–5 company profiles and country-specific analysis of 3–5 countries of your choice. Customizations are to be requested/discussed before making final order confirmation# as our team would review the same and check the feasibility
The report can be delivered in PDF/PPT format; we can also share excel dataset based on the request
Increased Adoption of Synthetic Data in Healthcare, Collaborations and Strategic Partnerships, Synthetic Data for Edge and IoT Applications
Growing Demand for Data Privacy, Advancements in AI and Machine Learning, Cost-Effective Data Generation
The global Synthetic Data Generation market is expected to grow at a CAGR of 36.5% during the forecast period 2024 - 2031
Trends and growth analysis reports related to Technology, Media and Telecommunications : READ MORE..
The Insight Partners performs research in 4 major stages: Data Collection & Secondary Research, Primary Research, Data Analysis and Data Triangulation & Final Review.
- Data Collection and Secondary Research:
As a market research and consulting firm operating from a decade, we have published and advised several client across the globe. First step for any study will start with an assessment of currently available data and insights from existing reports. Further, historical and current market information is collected from Investor Presentations, Annual Reports, SEC Filings, etc., and other information related to company’s performance and market positioning are gathered from Paid Databases (Factiva, Hoovers, and Reuters) and various other publications available in public domain.
Several associations trade associates, technical forums, institutes, societies and organization are accessed to gain technical as well as market related insights through their publications such as research papers, blogs and press releases related to the studies are referred to get cues about the market. Further, white papers, journals, magazines, and other news articles published in last 3 years are scrutinized and analyzed to understand the current market trends.
- Primary Research:
The primarily interview analysis comprise of data obtained from industry participants interview and answers to survey questions gathered by in-house primary team.
For primary research, interviews are conducted with industry experts/CEOs/Marketing Managers/VPs/Subject Matter Experts from both demand and supply side to get a 360-degree view of the market. The primary team conducts several interviews based on the complexity of the markets to understand the various market trends and dynamics which makes research more credible and precise.
A typical research interview fulfils the following functions:
- Provides first-hand information on the market size, market trends, growth trends, competitive landscape, and outlook
- Validates and strengthens in-house secondary research findings
- Develops the analysis team’s expertise and market understanding
Primary research involves email interactions and telephone interviews for each market, category, segment, and sub-segment across geographies. The participants who typically take part in such a process include, but are not limited to:
- Industry participants: VPs, business development managers, market intelligence managers and national sales managers
- Outside experts: Valuation experts, research analysts and key opinion leaders specializing in the electronics and semiconductor industry.
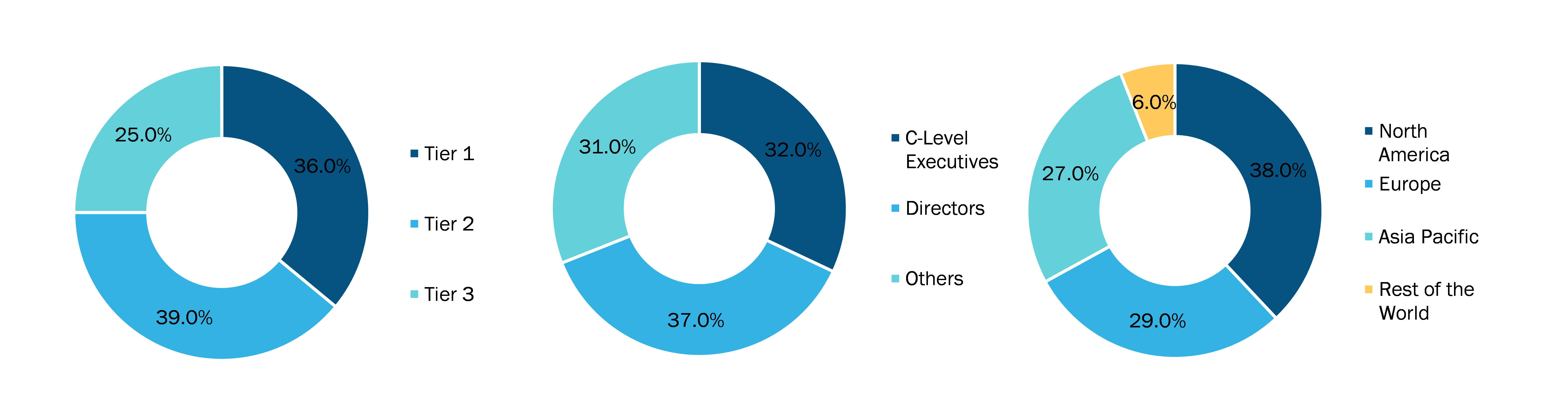
Below is the breakup of our primary respondents by company, designation, and region:
Once we receive the confirmation from primary research sources or primary respondents, we finalize the base year market estimation and forecast the data as per the macroeconomic and microeconomic factors assessed during data collection.
- Data Analysis:
Once data is validated through both secondary as well as primary respondents, we finalize the market estimations by hypothesis formulation and factor analysis at regional and country level.
- Macro-Economic Factor Analysis:
We analyse macroeconomic indicators such the gross domestic product (GDP), increase in the demand for goods and services across industries, technological advancement, regional economic growth, governmental policies, the influence of COVID-19, PEST analysis, and other aspects. This analysis aids in setting benchmarks for various nations/regions and approximating market splits. Additionally, the general trend of the aforementioned components aid in determining the market's development possibilities.
- Country Level Data:
Various factors that are especially aligned to the country are taken into account to determine the market size for a certain area and country, including the presence of vendors, such as headquarters and offices, the country's GDP, demand patterns, and industry growth. To comprehend the market dynamics for the nation, a number of growth variables, inhibitors, application areas, and current market trends are researched. The aforementioned elements aid in determining the country's overall market's growth potential.
- Company Profile:
The “Table of Contents” is formulated by listing and analyzing more than 25 - 30 companies operating in the market ecosystem across geographies. However, we profile only 10 companies as a standard practice in our syndicate reports. These 10 companies comprise leading, emerging, and regional players. Nonetheless, our analysis is not restricted to the 10 listed companies, we also analyze other companies present in the market to develop a holistic view and understand the prevailing trends. The “Company Profiles” section in the report covers key facts, business description, products & services, financial information, SWOT analysis, and key developments. The financial information presented is extracted from the annual reports and official documents of the publicly listed companies. Upon collecting the information for the sections of respective companies, we verify them via various primary sources and then compile the data in respective company profiles. The company level information helps us in deriving the base number as well as in forecasting the market size.
- Developing Base Number:
Aggregation of sales statistics (2020-2022) and macro-economic factor, and other secondary and primary research insights are utilized to arrive at base number and related market shares for 2022. The data gaps are identified in this step and relevant market data is analyzed, collected from paid primary interviews or databases. On finalizing the base year market size, forecasts are developed on the basis of macro-economic, industry and market growth factors and company level analysis.
- Data Triangulation and Final Review:
The market findings and base year market size calculations are validated from supply as well as demand side. Demand side validations are based on macro-economic factor analysis and benchmarks for respective regions and countries. In case of supply side validations, revenues of major companies are estimated (in case not available) based on industry benchmark, approximate number of employees, product portfolio, and primary interviews revenues are gathered. Further revenue from target product/service segment is assessed to avoid overshooting of market statistics. In case of heavy deviations between supply and demand side values, all thes steps are repeated to achieve synchronization.
We follow an iterative model, wherein we share our research findings with Subject Matter Experts (SME’s) and Key Opinion Leaders (KOLs) until consensus view of the market is not formulated – this model negates any drastic deviation in the opinions of experts. Only validated and universally acceptable research findings are quoted in our reports.
We have important check points that we use to validate our research findings – which we call – data triangulation, where we validate the information, we generate from secondary sources with primary interviews and then we re-validate with our internal data bases and Subject matter experts. This comprehensive model enables us to deliver high quality, reliable data in shortest possible time.
 이 보고서에 대한 무료 샘플을 받으세요
이 보고서에 대한 무료 샘플을 받으세요