The Synthetic Data Generation Market is expected to register a CAGR of 36.5% from 2025 to 2031, with a market size expanding from US$ XX million in 2024 to US$ XX Million by 2031.
The report is segmented by Offering (Solution/Platform and Services), Data Type (Tabular, Text, Image, and Video), Application (AI/ML Training & Development, Test Data Management). The global analysis is further broken-down at regional level and major countries. The report offers the value in USD for the above analysis and segments
Purpose of the ReportThe report Synthetic Data Generation Market by The Insight Partners aims to describe the present landscape and future growth, top driving factors, challenges, and opportunities. This will provide insights to various business stakeholders, such as:
- Technology Providers/Manufacturers: To understand the evolving market dynamics and know the potential growth opportunities, enabling them to make informed strategic decisions.
- Investors: To conduct a comprehensive trend analysis regarding the market growth rate, market financial projections, and opportunities that exist across the value chain.
- Regulatory bodies: To regulate policies and police activities in the market with the aim of minimizing abuse, preserving investor trust and confidence, and upholding the integrity and stability of the market.
Synthetic Data Generation Market Segmentation
Offering- Solution/Platform and Services
- Tabular
- Text
- Image
- Video
- AI/ML Training & Development
- Test Data Management
- North America
- Europe
- Asia Pacific
- Middle East and Africa
- South and Central America
Strategic Insights
Synthetic Data Generation Market Growth Drivers- Growing Demand for Data Privacy: Synthetic data enables organizations to create datasets without compromising user privacy. It provides an effective solution to mitigate privacy concerns, especially in sectors like healthcare and finance, where sensitive personal information is involved. By generating artificial data that mimics real-world data, companies can train AI models without exposing real identities, helping comply with data protection regulations such as GDPR.
- Advancements in AI and Machine Learning: The progress in AI and machine learning technologies has driven the demand for synthetic data. With the need for large, diverse datasets to train complex models, synthetic data generation helps address data scarcity, especially for niche or highly specific applications. It accelerates model development by offering high-quality, varied data without the need for costly or difficult-to-access real-world data.
- Cost-Effective Data Generation: Collecting and labeling real-world data can be expensive and time-consuming, especially for tasks like autonomous driving or medical research. Synthetic data generation reduces these costs significantly. It allows companies to create vast amounts of data quickly and affordably, enabling faster model training and testing. This is particularly beneficial in fields requiring continuous updates or large-scale simulations.
- Integration with AI and Deep Learning: The trend of integrating synthetic data with advanced AI and deep learning models is growing. AI-driven synthetic data generation tools are becoming more sophisticated, capable of creating high-quality, realistic datasets tailored to specific training needs. As deep learning techniques demand massive amounts of labeled data, the use of synthetic data to train models more efficiently is gaining traction across industries.
- Increased Adoption of Synthetic Data in Healthcare: With data privacy concerns and regulatory requirements tightening, the healthcare sector is increasingly adopting synthetic data for training machine learning models. Healthcare organizations are leveraging synthetic datasets to develop solutions for medical imaging, drug discovery, and patient care models while ensuring patient anonymity. This trend is fueled by the need for large datasets that can improve AI accuracy without compromising privacy.
- Collaborations and Strategic Partnerships: Many companies in the synthetic data market are forming strategic alliances to enhance their offerings. By collaborating with AI firms, research institutions, or healthcare providers, these companies aim to leverage each other's expertise and resources to advance synthetic data generation technologies. Such partnerships are contributing to the development of more tailored solutions for various industries, thereby accelerating the adoption of synthetic data.
- Autonomous Vehicle Development: The autonomous vehicle industry benefits from synthetic data for simulating a variety of driving scenarios that might be difficult or dangerous to recreate in the real world. Synthetic data enables the creation of diverse road conditions, weather situations, and traffic behaviors, which are vital for training and testing AI systems in self-driving cars. This opportunity helps speed up the development process while ensuring safety and reliability.
- AI and Machine Learning Research: Researchers in AI and machine learning can leverage synthetic data to train algorithms where real-world data might be scarce or not representative enough. In applications like natural language processing (NLP) or computer vision, synthetic data offers the flexibility to generate specific datasets for training purposes, reducing reliance on proprietary data and opening up new avenues for academic and industrial research.
- Financial Sector and Fraud Detection: In the financial industry, synthetic data can be used to simulate transactions, financial events, or fraudulent activities without exposing sensitive customer information. By training AI models on synthetic datasets, financial institutions can improve their fraud detection capabilities and mitigate risks while ensuring data privacy. This opportunity also enables the creation of more diverse datasets for better financial forecasting and market trend analysis.
Market Report Scope
Key Selling Points
- Comprehensive Coverage: The report comprehensively covers the analysis of products, services, types, and end users of the Synthetic Data Generation Market, providing a holistic landscape.
- Expert Analysis: The report is compiled based on the in-depth understanding of industry experts and analysts.
- Up-to-date Information: The report assures business relevance due to its coverage of recent information and data trends.
- Customization Options: This report can be customized to cater to specific client requirements and suit the business strategies aptly.
The research report on the Synthetic Data Generation Market can, therefore, help spearhead the trail of decoding and understanding the industry scenario and growth prospects. Although there can be a few valid concerns, the overall benefits of this report tend to outweigh the disadvantages.
REGIONAL FRAMEWORK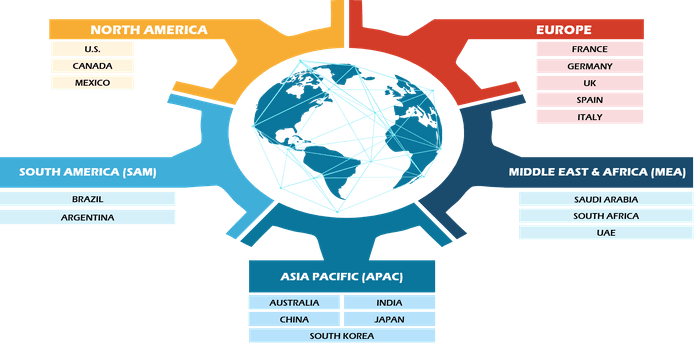

Have a question?

Naveen
Naveen will walk you through a 15-minute call to present the report’s content and answer all queries if you have any.
 Speak to Analyst
Speak to Analyst
- Sample PDF showcases the content structure and the nature of the information with qualitative and quantitative analysis.
- Request discounts available for Start-Ups & Universities

- Sample PDF showcases the content structure and the nature of the information with qualitative and quantitative analysis.
- Request discounts available for Start-Ups & Universities

Report Coverage
Revenue forecast, Company Analysis, Industry landscape, Growth factors, and Trends
Segment Covered
This text is related
to segments covered.

Regional Scope
North America, Europe, Asia Pacific, Middle East & Africa, South & Central America
Country Scope
This text is related
to country scope.
Frequently Asked Questions
Some of the customization options available based on the request are an additional 3–5 company profiles and country-specific analysis of 3–5 countries of your choice. Customizations are to be requested/discussed before making final order confirmation# as our team would review the same and check the feasibility
The report can be delivered in PDF/PPT format; we can also share excel dataset based on the request
Increased Adoption of Synthetic Data in Healthcare, Collaborations and Strategic Partnerships, Synthetic Data for Edge and IoT Applications
Growing Demand for Data Privacy, Advancements in AI and Machine Learning, Cost-Effective Data Generation
The global Synthetic Data Generation market is expected to grow at a CAGR of 36.5% during the forecast period 2024 - 2031
The Insight Partners performs research in 4 major stages: Data Collection & Secondary Research, Primary Research, Data Analysis and Data Triangulation & Final Review.
- Data Collection and Secondary Research:
As a market research and consulting firm operating from a decade, we have published many reports and advised several clients across the globe. First step for any study will start with an assessment of currently available data and insights from existing reports. Further, historical and current market information is collected from Investor Presentations, Annual Reports, SEC Filings, etc., and other information related to company’s performance and market positioning are gathered from Paid Databases (Factiva, Hoovers, and Reuters) and various other publications available in public domain.
Several associations trade associates, technical forums, institutes, societies and organizations are accessed to gain technical as well as market related insights through their publications such as research papers, blogs and press releases related to the studies are referred to get cues about the market. Further, white papers, journals, magazines, and other news articles published in the last 3 years are scrutinized and analyzed to understand the current market trends.
- Primary Research:
The primarily interview analysis comprise of data obtained from industry participants interview and answers to survey questions gathered by in-house primary team.
For primary research, interviews are conducted with industry experts/CEOs/Marketing Managers/Sales Managers/VPs/Subject Matter Experts from both demand and supply side to get a 360-degree view of the market. The primary team conducts several interviews based on the complexity of the markets to understand the various market trends and dynamics which makes research more credible and precise.
A typical research interview fulfils the following functions:
- Provides first-hand information on the market size, market trends, growth trends, competitive landscape, and outlook
- Validates and strengthens in-house secondary research findings
- Develops the analysis team’s expertise and market understanding
Primary research involves email interactions and telephone interviews for each market, category, segment, and sub-segment across geographies. The participants who typically take part in such a process include, but are not limited to:
- Industry participants: VPs, business development managers, market intelligence managers and national sales managers
- Outside experts: Valuation experts, research analysts and key opinion leaders specializing in the electronics and semiconductor industry.
Below is the breakup of our primary respondents by company, designation, and region:
Once we receive the confirmation from primary research sources or primary respondents, we finalize the base year market estimation and forecast the data as per the macroeconomic and microeconomic factors assessed during data collection.
- Data Analysis:
Once data is validated through both secondary as well as primary respondents, we finalize the market estimations by hypothesis formulation and factor analysis at regional and country level.
- 3.1 Macro-Economic Factor Analysis:
We analyse macroeconomic indicators such the gross domestic product (GDP), increase in the demand for goods and services across industries, technological advancement, regional economic growth, governmental policies, the influence of COVID-19, PEST analysis, and other aspects. This analysis aids in setting benchmarks for various nations/regions and approximating market splits. Additionally, the general trend of the aforementioned components aid in determining the market's development possibilities.
- 3.2 Country Level Data:
Various factors that are especially aligned to the country are taken into account to determine the market size for a certain area and country, including the presence of vendors, such as headquarters and offices, the country's GDP, demand patterns, and industry growth. To comprehend the market dynamics for the nation, a number of growth variables, inhibitors, application areas, and current market trends are researched. The aforementioned elements aid in determining the country's overall market's growth potential.
- 3.3 Company Profile:
The “Table of Contents” is formulated by listing and analyzing more than 25 - 30 companies operating in the market ecosystem across geographies. However, we profile only 10 companies as a standard practice in our syndicate reports. These 10 companies comprise leading, emerging, and regional players. Nonetheless, our analysis is not restricted to the 10 listed companies, we also analyze other companies present in the market to develop a holistic view and understand the prevailing trends. The “Company Profiles” section in the report covers key facts, business description, products & services, financial information, SWOT analysis, and key developments. The financial information presented is extracted from the annual reports and official documents of the publicly listed companies. Upon collecting the information for the sections of respective companies, we verify them via various primary sources and then compile the data in respective company profiles. The company level information helps us in deriving the base number as well as in forecasting the market size.
- 3.4 Developing Base Number:
Aggregation of sales statistics (2020-2022) and macro-economic factor, and other secondary and primary research insights are utilized to arrive at base number and related market shares for 2022. The data gaps are identified in this step and relevant market data is analyzed, collected from paid primary interviews or databases. On finalizing the base year market size, forecasts are developed on the basis of macro-economic, industry and market growth factors and company level analysis.
- Data Triangulation and Final Review:
The market findings and base year market size calculations are validated from supply as well as demand side. Demand side validations are based on macro-economic factor analysis and benchmarks for respective regions and countries. In case of supply side validations, revenues of major companies are estimated (in case not available) based on industry benchmark, approximate number of employees, product portfolio, and primary interviews revenues are gathered. Further revenue from target product/service segment is assessed to avoid overshooting of market statistics. In case of heavy deviations between supply and demand side values, all thes steps are repeated to achieve synchronization.
We follow an iterative model, wherein we share our research findings with Subject Matter Experts (SME’s) and Key Opinion Leaders (KOLs) until consensus view of the market is not formulated – this model negates any drastic deviation in the opinions of experts. Only validated and universally acceptable research findings are quoted in our reports.
We have important check points that we use to validate our research findings – which we call – data triangulation, where we validate the information, we generate from secondary sources with primary interviews and then we re-validate with our internal data bases and Subject matter experts. This comprehensive model enables us to deliver high quality, reliable data in shortest possible time.
 Get Free Sample For
Get Free Sample For