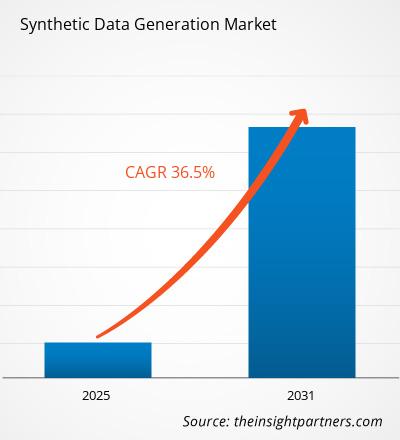
预计合成数据生成市场在 2025 年至 2031 年期间的复合年增长率为 36.5%,市场规模将从 2024 年的 XX 百万美元扩大到 2031 年的 XX 百万美元。
该报告按产品(解决方案/平台和服务)、数据类型(表格、文本、图像和视频)、应用(AI/ML 训练与开发、测试数据管理)进行细分。全球分析进一步细分为区域和主要国家。报告提供了上述分析和细分的美元价值。
报告目的
Insight Partners 发布的《合成数据生成市场》报告旨在描述当前的市场格局和未来增长、主要驱动因素、挑战和机遇。这将为各业务利益相关者提供见解,例如:
- 技术提供商/制造商:了解不断变化的市场动态并了解潜在的增长机会,使他们能够做出明智的战略决策。
- 投资者:对市场增长率、市场财务预测以及整个价值链中存在的机会进行全面的趋势分析。
- 监管机构:规范市场政策和警察活动,旨在最大限度地减少滥用行为,维护投资者的信任和信心,维护市场的完整性和稳定性。
合成数据生成市场细分
奉献
- 解决方案/平台和服务
数据类型
- 表格
- 文本
- 图像
- 视频
应用
- 人工智能/机器学习培训与发展
- 测试数据管理
地理
- 北美
- 欧洲
- 亚太地区
- 中东和非洲
- 南美洲和中美洲
定制此报告以满足您的要求
您可以免费定制任何报告,包括本报告的部分内容、国家级分析、Excel 数据包,以及为初创企业和大学提供优惠和折扣
合成数据生成市场:战略洞察

- 获取此报告的顶级关键市场趋势。此免费样品将包括数据分析,从市场趋势到估计和预测。
合成数据生成市场的增长动力
- 数据隐私需求日益增长:合成数据使组织能够在不损害用户隐私的情况下创建数据集。它为缓解隐私问题提供了有效的解决方案,尤其是在涉及敏感个人信息的医疗保健和金融等行业。通过生成模拟真实世界数据的人工数据,企业可以在不暴露真实身份的情况下训练人工智能模型,从而有助于遵守《通用数据保护条例》(GDPR)等数据保护法规。
- 人工智能和机器学习的进步:人工智能和机器学习技术的进步推动了对合成数据的需求。由于需要大量多样化的数据集来训练复杂的模型,合成数据生成有助于解决数据稀缺问题,尤其适用于小众或高度特定的应用。它通过提供高质量、多样化的数据来加速模型开发,而无需昂贵或难以获取的真实数据。
- 经济高效的数据生成:收集和标记真实世界的数据可能成本高昂且耗时,尤其是在自动驾驶或医学研究等任务中。合成数据生成可以显著降低这些成本。它使公司能够快速且经济地创建海量数据,从而加快模型训练和测试的速度。这在需要持续更新或大规模模拟的领域尤其有益。
合成数据生成市场未来趋势
- 与人工智能和深度学习的融合:将合成数据与先进的人工智能和深度学习模型相融合的趋势日益增长。人工智能驱动的合成数据生成工具正变得越来越复杂,能够根据特定的训练需求创建高质量、逼真的数据集。由于深度学习技术需要大量的标记数据,使用合成数据来更高效地训练模型正在各行各业获得越来越大的关注。
- 医疗保健领域合成数据的采用日益增多:随着数据隐私担忧和监管要求的日益严格,医疗保健行业越来越多地采用合成数据来训练机器学习模型。医疗保健机构正在利用合成数据集开发医学成像、药物研发和患者护理模型的解决方案,同时确保患者的匿名性。这一趋势源于对能够在不损害隐私的情况下提高人工智能准确性的大型数据集的需求。
- 合作与战略伙伴关系:合成数据市场中的许多公司正在建立战略联盟,以增强其产品服务。通过与人工智能公司、研究机构或医疗保健提供商合作,这些公司旨在利用彼此的专业知识和资源,推进合成数据生成技术的发展。此类伙伴关系有助于为各行各业开发更具针对性的解决方案,从而加速合成数据的普及。
合成数据生成市场机会
- 自动驾驶汽车开发:自动驾驶汽车行业受益于合成数据,它可以模拟各种在现实世界中难以重现或存在危险的驾驶场景。合成数据能够创建各种路况、天气状况和交通行为,这对于训练和测试自动驾驶汽车的人工智能系统至关重要。这一机会有助于加快开发进程,同时确保安全性和可靠性。
- 人工智能和机器学习研究:人工智能和机器学习领域的研究人员可以利用合成数据来训练算法,因为现实世界的数据可能稀缺或缺乏代表性。在自然语言处理 (NLP) 或计算机视觉等应用中,合成数据可以灵活地生成用于训练的特定数据集,从而减少对专有数据的依赖,并为学术和工业研究开辟新的途径。
- 金融行业与欺诈检测:在金融行业,合成数据可用于模拟交易、金融事件或欺诈活动,且不会泄露敏感的客户信息。通过在合成数据集上训练人工智能模型,金融机构可以提升其欺诈检测能力,降低风险,同时确保数据隐私。这一机会也有助于创建更多样化的数据集,从而更好地进行财务预测和市场趋势分析。
合成数据生成市场区域洞察
Insight Partners 的分析师已详尽阐述了预测期内影响合成数据生成市场的区域趋势和因素。本节还讨论了北美、欧洲、亚太地区、中东和非洲以及南美和中美洲的合成数据生成市场细分和地域分布。
- 获取合成数据生成市场的区域特定数据
合成数据生成市场报告范围
| 报告属性 | 细节 |
|---|---|
| 2024年的市场规模 | XX百万美元 |
| 2031年的市场规模 | XX百万美元 |
| 全球复合年增长率(2025-2031) | 36.5% |
| 史料 | 2021-2023 |
| 预测期 | 2025-2031 |
| 涵盖的领域 | 通过提供
|
| 覆盖地区和国家 | 北美
|
| 市场领导者和主要公司简介 |
|
合成数据生成市场参与者密度:了解其对业务动态的影响
合成数据生成市场正在快速增长,这得益于终端用户需求的不断增长,而这些需求的驱动因素包括消费者偏好的演变、技术进步以及对产品优势的认知度的提升。随着需求的增长,企业正在扩展产品线,不断创新以满足消费者需求,并抓住新兴趋势,从而进一步推动市场增长。
市场参与者密度是指特定市场或行业内企业或公司的分布情况。它表明特定市场空间内竞争对手(市场参与者)的数量相对于其规模或总市值而言。
在合成数据生成市场运营的主要公司有:
- 微软
- 谷歌
- IBM
- AWS
- 英伟达
- OpenAI
免责声明:以上列出的公司没有按照任何特定顺序排列。
- 获取合成数据生成市场顶级关键参与者概览
主要卖点
- 全面覆盖:该报告全面涵盖了合成数据生成市场的产品、服务、类型和最终用户的分析,提供了整体概况。
- 专家分析:本报告基于对行业专家和分析师的深入了解而编写。
- 最新信息:该报告涵盖了最新信息和数据趋势,确保了业务相关性。
- 定制选项:此报告可以定制以满足特定客户要求并适合业务策略。
因此,这份关于合成数据生成市场的研究报告可以帮助引领解读和理解行业现状及增长前景。尽管存在一些合理的担忧,但本报告的总体优势往往大于劣势。
- 历史分析(2 年)、基准年、预测(7 年)及复合年增长率
- PEST 和 SWOT 分析
- 市场规模价值/数量 - 全球、区域、国家
- 行业和竞争格局
- Excel 数据集

Report Coverage
Revenue forecast, Company Analysis, Industry landscape, Growth factors, and Trends
Segment Covered
This text is related
to segments covered.

Regional Scope
North America, Europe, Asia Pacific, Middle East & Africa, South & Central America
Country Scope
This text is related
to country scope.
常见问题
Some of the customization options available based on the request are an additional 3–5 company profiles and country-specific analysis of 3–5 countries of your choice. Customizations are to be requested/discussed before making final order confirmation# as our team would review the same and check the feasibility
The report can be delivered in PDF/PPT format; we can also share excel dataset based on the request
Increased Adoption of Synthetic Data in Healthcare, Collaborations and Strategic Partnerships, Synthetic Data for Edge and IoT Applications
Growing Demand for Data Privacy, Advancements in AI and Machine Learning, Cost-Effective Data Generation
The global Synthetic Data Generation market is expected to grow at a CAGR of 36.5% during the forecast period 2024 - 2031
Trends and growth analysis reports related to Technology, Media and Telecommunications : READ MORE..
The Insight Partners performs research in 4 major stages: Data Collection & Secondary Research, Primary Research, Data Analysis and Data Triangulation & Final Review.
- Data Collection and Secondary Research:
As a market research and consulting firm operating from a decade, we have published and advised several client across the globe. First step for any study will start with an assessment of currently available data and insights from existing reports. Further, historical and current market information is collected from Investor Presentations, Annual Reports, SEC Filings, etc., and other information related to company’s performance and market positioning are gathered from Paid Databases (Factiva, Hoovers, and Reuters) and various other publications available in public domain.
Several associations trade associates, technical forums, institutes, societies and organization are accessed to gain technical as well as market related insights through their publications such as research papers, blogs and press releases related to the studies are referred to get cues about the market. Further, white papers, journals, magazines, and other news articles published in last 3 years are scrutinized and analyzed to understand the current market trends.
- Primary Research:
The primarily interview analysis comprise of data obtained from industry participants interview and answers to survey questions gathered by in-house primary team.
For primary research, interviews are conducted with industry experts/CEOs/Marketing Managers/VPs/Subject Matter Experts from both demand and supply side to get a 360-degree view of the market. The primary team conducts several interviews based on the complexity of the markets to understand the various market trends and dynamics which makes research more credible and precise.
A typical research interview fulfils the following functions:
- Provides first-hand information on the market size, market trends, growth trends, competitive landscape, and outlook
- Validates and strengthens in-house secondary research findings
- Develops the analysis team’s expertise and market understanding
Primary research involves email interactions and telephone interviews for each market, category, segment, and sub-segment across geographies. The participants who typically take part in such a process include, but are not limited to:
- Industry participants: VPs, business development managers, market intelligence managers and national sales managers
- Outside experts: Valuation experts, research analysts and key opinion leaders specializing in the electronics and semiconductor industry.
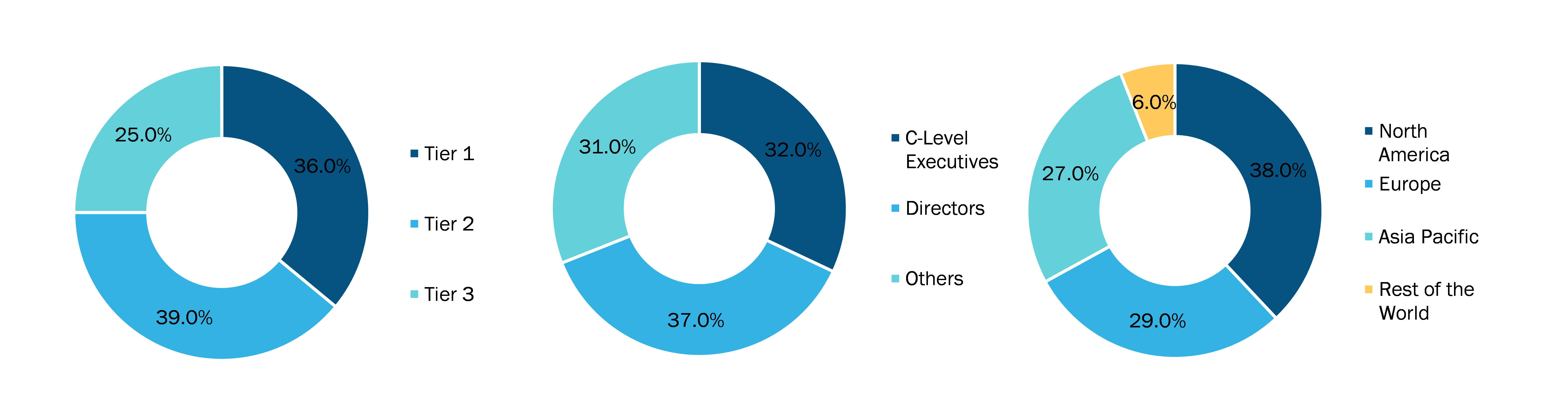
Below is the breakup of our primary respondents by company, designation, and region:
Once we receive the confirmation from primary research sources or primary respondents, we finalize the base year market estimation and forecast the data as per the macroeconomic and microeconomic factors assessed during data collection.
- Data Analysis:
Once data is validated through both secondary as well as primary respondents, we finalize the market estimations by hypothesis formulation and factor analysis at regional and country level.
- Macro-Economic Factor Analysis:
We analyse macroeconomic indicators such the gross domestic product (GDP), increase in the demand for goods and services across industries, technological advancement, regional economic growth, governmental policies, the influence of COVID-19, PEST analysis, and other aspects. This analysis aids in setting benchmarks for various nations/regions and approximating market splits. Additionally, the general trend of the aforementioned components aid in determining the market's development possibilities.
- Country Level Data:
Various factors that are especially aligned to the country are taken into account to determine the market size for a certain area and country, including the presence of vendors, such as headquarters and offices, the country's GDP, demand patterns, and industry growth. To comprehend the market dynamics for the nation, a number of growth variables, inhibitors, application areas, and current market trends are researched. The aforementioned elements aid in determining the country's overall market's growth potential.
- Company Profile:
The “Table of Contents” is formulated by listing and analyzing more than 25 - 30 companies operating in the market ecosystem across geographies. However, we profile only 10 companies as a standard practice in our syndicate reports. These 10 companies comprise leading, emerging, and regional players. Nonetheless, our analysis is not restricted to the 10 listed companies, we also analyze other companies present in the market to develop a holistic view and understand the prevailing trends. The “Company Profiles” section in the report covers key facts, business description, products & services, financial information, SWOT analysis, and key developments. The financial information presented is extracted from the annual reports and official documents of the publicly listed companies. Upon collecting the information for the sections of respective companies, we verify them via various primary sources and then compile the data in respective company profiles. The company level information helps us in deriving the base number as well as in forecasting the market size.
- Developing Base Number:
Aggregation of sales statistics (2020-2022) and macro-economic factor, and other secondary and primary research insights are utilized to arrive at base number and related market shares for 2022. The data gaps are identified in this step and relevant market data is analyzed, collected from paid primary interviews or databases. On finalizing the base year market size, forecasts are developed on the basis of macro-economic, industry and market growth factors and company level analysis.
- Data Triangulation and Final Review:
The market findings and base year market size calculations are validated from supply as well as demand side. Demand side validations are based on macro-economic factor analysis and benchmarks for respective regions and countries. In case of supply side validations, revenues of major companies are estimated (in case not available) based on industry benchmark, approximate number of employees, product portfolio, and primary interviews revenues are gathered. Further revenue from target product/service segment is assessed to avoid overshooting of market statistics. In case of heavy deviations between supply and demand side values, all thes steps are repeated to achieve synchronization.
We follow an iterative model, wherein we share our research findings with Subject Matter Experts (SME’s) and Key Opinion Leaders (KOLs) until consensus view of the market is not formulated – this model negates any drastic deviation in the opinions of experts. Only validated and universally acceptable research findings are quoted in our reports.
We have important check points that we use to validate our research findings – which we call – data triangulation, where we validate the information, we generate from secondary sources with primary interviews and then we re-validate with our internal data bases and Subject matter experts. This comprehensive model enables us to deliver high quality, reliable data in shortest possible time.
 获取此报告的免费样本
获取此报告的免费样本